🇫🇷 About PAISS 🔗
5-day summer school from 2-6 July 2018, held at Inria Grenoble, co-organized by Inria/Univ. Grenoble Alpes and NAVER LABS Europe. All the slides for the sessions have been uploaded on the official website. What follows are just my personal notes which I will be updating and plugging holes in as I go through the official slides. Feel free to comment!
Some statistics 🔗
44 nationalities, 25% women, 60% students, 15% academics, 25% professional
Legend for the notes 🔗
- 📑 : has relevant publication (ideally hyperlinked)
- ❓: missing information/needs clarification
- 👍: advantage
- ❌ : disadvantage
- 👀 : look up later
Yann LeCun: 🌇 Deep learning: past, present, and future 🔗
VP & Chief AI Scientist @ FB, Professor @ NYU
Supervised learning 🎓 is good for… 🔗
| input | output |
|---|---|
| speech | words |
| image | categories |
| portrait | name |
| photo | caption |
| text | topic.. |
Traditional ML 🔗
hand-engineered feature extractor -> trainable classifier
Deep learning 🔗
end-to-end learning, from low- to high-level features, to be fed into a trainable classifier, all with adaptable parameters
layers
allow more flexible functions to be modelled
objective function
discrepancy between expected and predicted output
optimization/training
- stochastic optimization, aka SGD, although it’s not technically “descent”
in practice, we do minibatch (10, 30, 100 samples) instead of a single sample
Minibatch SGD
- if all examples in minibatch are sort of orthogonal (diff categories…) then it’s good
- but if there’s any redundancy, then it hurts (waste of time) to have overly large batch
- if batch too small, then it’s not fully utilizing the parallelization capabilities of your hardware
- stochastic gradient introduces some noise, maybe improves generalization by adding stochasticity (but it’s not well understood)
backprop
🗨 “It’s surprising that it took until the 1980’s to apply the chain rule to ML.” 🗨 “Non-linear functions are technically not differentiable everywhere so we’re actually computing subgradients. Please add ‘sub’ everytime I say ‘gradients’ to keep the mathematicians happy.” Gradients not being true gradients has some implications, e.g. local curvature is not representative of function.
🗨 Projector isssues
“I think I figured out what’s wrong with the projector. It’s missing a channel so all the red highlights appear grey. So please just reprogram your visual cortex.”
Yann
Timeline (Past and Present) 🔗
AI winter 🔗
🗨 “It’s alchemy, it never works… Only Yann can make it work.”
Early Work with DARPA 🔗
- DAVE, LAGR project
- semantic segmentation with convnets for off-road driving
“Semantic segmentation with CNN”: submitted to CVPR, rejected by all 3 reviewers
Semantic segmentation used by MobilEye, and NVIDIA, for self-driving cars
- Today, NVIDIA’s still working on autonomous driving, able to drive 10 miles on country road
CNN’s 🔗
Alexnet won ImageNet competition on GPU’s
VGG, GoogLeNet
overall trend 📉 drop in loss (improvement in performance) but also :chart-with-upwards-trend: inflation in layers
Resnet
good for many layers, architecture is suitable for very deep networks
densenet
pretraining on 3.5b instagram images with hashtags
- predict hashtags
- hashtags are weak labels; can represent content of the images or something completely different
- then chop off the last few layers and retrain on imagenet/coco/pascal
- then boom better performance
image segmentation 🔗
Mask R-CNN
Predicts bounding box and draws a mask of object for each region of interest
Facebook’s Detectron
DensePose
Real-time body pose estimation
- WOW the demo looks so sick
- Trained on a single GPU
Other applications of CNN’s 🔗
Facebook uses them for translation
Encoder-decoder with convolutional and deconvolutional networks
medical image analysis
- V-Net
- CUMED
- PROMISE12 dataset
speech recognition
physic
robotics
e.g. @ CERN, filter high-particle trajectories…
Apply CNN to non-Euclidean data
Using the Spectral domain
Has interesting property: convolutions are diagonal operators in fourier space. Take FT of image, multiply by the kernel with the diagonal operator, then get the inverse, and you get the convolution of the image. Can think of convolution as a graph where each node is a pixel connected to nearest neighbours
- “Convolutional Nets on Irregular Graphs: 📑 Geometric deep learning: going beyond Euclidean data Bronstein, 2016
- Convolution in a spectral CNN is done by computing graph Laplacians and getting the Laplacian eigenvectors
- Graphs can represent language, social networks,…
- 📑 “ConvNets on Graphs” Bresson 2018
- 👀 Refer to IPAM workshop for more details
graph convnet regular grid graph standard convnet fixed irregular graph spectral convnet dynamic irregular graph graph convnet - “Convolutional Nets on Irregular Graphs: 📑 Geometric deep learning: going beyond Euclidean data Bronstein, 2016
Random paper
Using spectral graph convolutions to learn brain surface data
Reinforcement learning 🔗
Incredible success in games, like Go and Atari.
FAIR has open-sourced ELF OpenGo.
❌ Pure RL requires way too many trials to learn a task
📑 Rainbow: Combining Improvements in Deep Reinforcement Learning (Hessel ArXiv 1710.02298) Examines six extensions to the DQN algorithm and empirically studies their combination, with suggestions for improving efficiency.
FB open source 🔗
PyTorch
FAISS
Fast similarity search for nearest neighbours (C++/CUDA).
-
Training environment for dialog systems.
FastText
Text classification, non-deep learning.
🌅 What’s missing? (The future) 🔗
Marry DL with reasoning via differentiable programming 🔗
Augmenting neural nets with memory modules, as kind of a hippocampus
DeepMind’s Differential Neural Computer (DNC)
DNC is the successor of Neural Turing Machine (NTM, 2014)
- Stacked LSTM controller that reads from and writes to an external memory, in addition to accepting input and producing output.
- Entire architecture is differentiable, so gradient-base optimizers can be applied.
- Generalized architecture that can perform a range of tasks from planning to natural language understanding.
Memory Networks (Weston, 2014), Dialog through Prediction (Weston, 2016)
Stacked-augmented neural net
EntNet: Entity RNN
📑 “Tracking the world state with recurrent entity networks” Tell a story, then answer a question about it.
👀 📑 Inferring and executing programs for visual reasoning
Like module networks!
🐕👶 Enormous knowledge/understanding from little observations… 🔗
Like how animals and humans learn a good world model
Emmanuel Dupoux: early conceptual acquisition in infants

- interestingly, baby chickens have a notion of stability and support hardwired from birth
“prediction is the essence of intelligence”
try to predict what happens according to world model, and pay attention when you’re wrong
common sense is the ability to fill in the blanks
learning predictive models of the world (common sense, predict…)
- pieter abbeel, chelsea finn
biggest challenge: need to predict under uncertainty, invariant prediction
- training samples are merely representatives of a whole manifold of outputs
e.g. a standing pen may fall in any direction in 360 degrees
we don’t know how to represent probability distributions in high dimensional, continuous spaces
how to predict the next image?
possible solution: adversarial training
train a second network to tell the first if their prediction is on the ribbon (manifold) or not
low energy for good predictions, high energy for bad predictions
📑 faces “invented” by a neural net, by facebook
- “they look really good… if you look at them on a screen that actually has a red channel”
3 types of learning
type of learning feedback level decription reinforcement learning weak feedback predict a scalar reward given once in a while supervised learning medium feedback predict output for each input self-supervised predictive learning a lot of feedback predict any part of its input for any observed part Self-supervised predictive learning is the most similar to natural learning.
- e.g. Predict future frames in videos
Diane Larlus: 🖼 Visual Search 🔗
Senior scientist @ NAVERLABS
💬 “It was a bit of a gamble, with the due date coming very soon” 👶
Visual search 🔗
From query image, represent it as descriptor and find images with similar descriptors.
Lots of applications 🔗
Shopping from reverse image search, ambient intelligence (robots expected to interact with humans with person re-identification)…
Inherent ambiguity 🔗
What does the user mean with a single query image? -> It’s application dependent
How to design for applications?
Either inject prior information, or leverage training.
- The latter is most popular with recent methods.
Object search 🔗
The most studied task in the field, with largest set of mature applications
Families of representations 🔗
“Legacy” methods 🔗
Early methods
Used low-level cues, not enough for capturing semantic meaning
- color histograms, texture, and shape descriptors, e.g. QBIC project
Local representations
Why? Because it’s challenging to capture all of these invariances (background, color…) in a global representation, so each image is represented as a set of features.
Evaluation of local descriptors
- 👍more adapted
❌ require more sophisticated matching
Trade-off between invariance and discriminativeness
More specifically, there’s a trade-off among 3 properties:
(compact - invariant - discriminative)
Interest point detectors
- Harris, Hessian, Hessian-Affine, MSER etc.
People still use these to classify interest points.
Local descriptors
- SIFT (most popular), SURF, LBP
Pipeline overview for local representations
- select locations in input image with interest point detectors
- 👍provides coarse object localization as a side effect
- generate local descriptors
- pairwise matching between all local descriptors of query and other image
- boils down to like a nearest-neighbour match in SIFT descriptors
- ❌ can be expensive
- generate local pairwise matches
- geometrical verification with RANSAC etc. to clean images (costly… but doing on a shortlist)
- find geometric transformation that fits highest number of matches
- retain only images with enough matches of estimated transformation
- ❌ costly — only can use a shortlist of images
- select locations in input image with interest point detectors
How to speed up pairwise matching (step 3)?
Approximate Neighbour Search (ANN)
Randomized K-d trees
Using priority queue; 👀 How k-d trees work with queues
Locality-sensitive hashing (LSH)))
randomized hashing technique
spectral hashing, semantic hashing (data-driven hashing)
Quantization
generate bins of the descriptor space, called a “visual codebook” of labelled regions of space/buckets of images
📑 Leverage quantization for efficient retrieval (Zisserman)
Inverted file mapping from bins (regions) to candidate images
Global representations
Some approaches are:
VLAD (Vector of Locally Aggregated Descriptors)
bag-of-visual-features
represent images as a histogram of occurrences
how to refine the coarse description?
more entries in the visual codebook (expensive tho)
add higher order statistics, e.g. mean and variance
❓ fisher-vector
probabilistic codebook of mixed gaussians, figure out which parameter needs to be adjusted
Conclusion
There are 2 dominant approaches:
Matching-based methods with local representations
- 👍Highest accuracy
- ❌ Expensive to do matching and geometry verification
Aggregation methods with global representations
The inverse of local representations, namely:
- ❌ Lower accuracy
- 👍 Faster and more efficient
Deep representations 🔗
With pretrained CNN’s
How to apply AlexNet, meant for classification, to retrieval?
Naive way: use CNN as feature extractor
- ❌ not competitive with “legacy” methods, performance-wise
- ❌ hard to do intra-class generalization
- ❌ low resolution and distorted aspect ratio
Hybrid methods combining CNN representations with old representations
NetVlad
Add VLAD (Vector of Locally Aggregated Descriptors) block at the end of the CNN. Every step is differentiable — can train with backpropagation.
Fisher Vector representation with fully-connected layers
Pretraining limitations:
- Images need to be distorted to fit fixed input requirements, losing valuable information due to:
- reduced resolution
- wrong aspect ratio
- Still needs to use a classification loss, when what we’re doing in retrieval is ranking
- Noisy, with mistakes
- Images need to be distorted to fit fixed input requirements, losing valuable information due to:
With R-MAC descriptor
Can capture details of images — can take advantage of high-resolution images. Other similar descriptors like R-MAC are: - SPoC
- CroW
- Generalize-mean polling (GeM)
Instead of a fully-connected layer, you can use GeM etc.
Corresponding similarity measures
?
trade-offs in similarity search
accuracy (exhaustive search)
memory (RAM) compression
search speed (pruning)
👀 Look at Herve Jegou’s tutorials on compression, product quantization (PQ)
What worked for the landmark recognition challenge @ CVPR18? 🔗
CNN-based global features win 🔗
- RMAC, differentiable RMAC, generalized-mean pooling
- Some combine with local features
- SIFT, DELPH, for re-ranking and query expansion
All have query expansion and/or diffusion 🔗
If we are confident that image A is very similar to query image Q, we can also return the images retrieved from image A to augment query on Q.
Multi-resolution, ensembling were used 🔗
🚶🚷 Person re-identification 🔗
Identify the same person from different images of that person. This is challenging because often, the bounding boxes of the people are not aligned; may be cropped/occluded. Many recent approaches propose task-specific representations which aim to fix the alignment issue:
- spatial transformer networks
- pose estimation; part or joint localization..
- attention mechanism
We can also use a global representation:
📑 “In defense of global representations for person re-identification” 🔗
📑 “Re-ID done right” 🔗
*Uses grad-CAM to figure out which areas of the image matter, as well as which dimensions.
Semantic retrieval 🔗
Instance-level retrieval works on single objects only, whereas semantic retrieval is about retrieving the full scene.
Summary 🔗
- Local descriptors still relevant
- Essential ingredients for image retrieval recipe:
- Clean training set
- Appropriate architecture
- Learning to rank
Still missing… 🔗
Implicit scene understanding
Need to understand interactions, categories… activity recognition and classification, maybe building graphs… build complex visual search. We can do this by
- Leveraging image captions
- Doing explicit scene modeling
- Leveraging other CV components
Questions 🔗
Contrastive loss (two streams) vs. triplet loss? 🔗
Which is better depends on the system, empirically there’s no clear winner.
A random open-source project that looks similar to their approach 🔗
Siamese network/triplet loss: O(N^3) for exhaustive search. How to improve this? 🔗
It’s in the implementation details, namely hard triplet mining. Refer to this open-source PyTorch implementation for guidance.
Remaining questions 🔗
- Is having a fixed margin in the triplet loss too inflexible, i.e. doesn’t allow for discriminating between more and less similar items?
- Can we have clothing invariance in person re-identification?
Andrew Zisserman: 🎓 Self-supervised Learning 🔗
Computer vision, recovering 3D structure from image etc.
Why self-supervision? 🔗
- Expense of producing datasets
- Hard to obtain, e.g. 🏥 medical data
- Untapped and vast amount of unlabelled (or weakly-labelled) images/videos on the Internet
- e.g. Flickr, Instagram
- Babies and animals do self-supervised learning
What is self-supervision? 🔗
The task is to define a proxy loss, and implicitly learn something of semantic significance. It’s often complementary, and combining improves performance.
📑 Unsupervised visual representation learning by context prediction (Carl Doersch) 🔗
Proxy task: predict relative position of 2 subregions within a larger image.
- This is just a proxy task we don’t really care about, we really wanna learn something else, e.g. categories
Using a proxy task (relative positioning), we got weights of a network similar to that trained by ImageNet AlexNet (supervised).
- An autoencoder wouldn’t have learnt it so well.
❓So the convolutional layers were trained in a self-supervised manner… but how did they train the final softmax classifier layer? Was it supervised?
Evaluation
PASCAL VOC (Visual object classes) detection benchmark: draw bounding boxes
- imagenet labels: 56.8%
- relative positioning: 51%
- no pretraaining; 46%
Self-supervised learning from images 🔗
tricky details 🔗
You always need to check (in some creative way I guess) whether the network is truly solving the problem *the way you want.
Avoid trivial shortcuts
An example of a trivial shortcut the network (Doersch) could take is to naively use a nearest-neighbour heuristic to join the edges of adjacent regions. We can avoid this by
- including a gap between patches
- jittering pixels
…as well as not-so-trivial shortcuts (a cautionary tale…)
- network was using chromatic aberration to infer the
x,ycoordinates from the image (Doersch)
- network was using chromatic aberration to infer the
Methods 🔗
- split-brain autoencoders
- ResNet-101
proxy tasks 🔗
relative positioning of patches
automatic colorization (convert to black and white, try to colorize)
📑 image transformations (2018) !!! rotate image and predict right side up
Rotation approach almost closed the gap between ImageNet and self-supervision.
Self-supervised learning from videos 🔗
📑 “Shuffle and Learn” (Misra, 2016) 🔗
- Sample triplets of frames, some in the right order and others jumbled up.
- Train network to predict whether sequence is valid or jumbled up
That is, “Given a start and end frame, could the middle one belong in between them temporally?”
Sampling
Be careful to avoid sampling trivial sequences, e.g. 3 identical frames. Make sure there is some optical flow/changes in frame motion between the 3 frames, otherwise all 3 permutations are valid.
❓Human pose estimation 🔗
Summary: lessons so far 🔗
Important to select/sample informative data in training 🔗
- We often use heuristics e.g. frame motion
SSL using the arrow of time :archery: (Donglai Wei, CVPR) 🔗
Coldplay’s “The Scientist” music video 🔗
Chris Martin was mouthing all the words backwards!!!!!!!!
Interestingly, this paper used the Flickr dataset 🔗
- Not a dedicated dataset, just random organic videos.
- Shows that self-supervised learning is applicable for user-generated content.
Task 🔗
Proxy task: predict if a video is playing forwards or backwards. What cues does the network use to make the prediction?
Strong cues for the arrow of time
- gravity
- entropy
- friction
- causality
Weak/no cues (throw these training examples out!)
- constant motion
- repetitions/cyclic
- symmetric in time
Some gotchas/trivial shortcuts 🔗
- The black stripes above and below the frame had some chromatic information?
- Cinematic conventions that cinematographers tend to do, such as
- Zooming in, and not out
- The classic camera tilt-down
So we need to remove all black bars, and all zoom/tilt scenes, from the training samples.
👀 SSL using temporal coherence of color 🏳️🌈 (Self-Supervised Tracking via Video Colorization) 🔗
Color is mostly temporally coherent. Proxy task: Colorize all frames of a gray scale version using a reference single colorized frame.
Cool visualization 🔗
Project embedding to 3 dimensions and plot as RGB
Self-supervised learning from videos with sound (audio-visual co-supervision) 🔗
📑 Audio-visual embedding (AVE-Net) There are two properties to tease out via proxy tasks:
Semantic consistency between sound and image 🔗
What looks like a drum will sound like a drum… so what does a drum sound like? Task: Does this single video frame match this sound snippet?
Synchronization between sound and image 🔗
When you hit the drum, a sound will play.
We end up learning… 🔗
- Great representations of audio and sound
- Cross-modal retrieval, e.g. query on image, retrieve audio
- ‘What is making that sound?’ producing localization heatmaps on frame
📑 “Objects that Sound”, ICCV 2017
Other examples of audio-visual co-supervision 🔗
📑 Talking Heads: face-speech synchronization
“Out of Time: Automatic lip sync in the wild” (Zisserman, 2016) Proxy task: Is the audio out of sync with the video?
📑 “Audio-visual scene analysis with self-supervised multisensory features” (Andrew Owens, Alyosha Efros, 2018)
- Also learning by misaligned audio
- Learning an attention mechanism, like “what is making that sound?” as well
Summary 🔗
Enables learning without supervision 🔗
Classification performance is on par with ImageNet-trained models.
SSL from videos with sound 🔗
- learn to localize sounds
- intra- and cross-modal retrieval
- tasks not just a proxy, e.g. synchronization, attention, applicable directly
Applicable to other domains with paired signals 🔗
- face and voice
- infrared/visible
- RGB/D
- Stereo streams
❓Teething problems 🔗
❓Humans have replay buffers, when they’re sleeping, etc. 🔗
Questions 🔗
How do you come up with proxy tasks? 🔗
Do you go bottom-up:
- “How can I mess with this unlabelled data and formulate a task for a network to solve?”
Or do you go backwards, like,
“How do I leverage the temporal coherence of color?”
Answer
Both! Also one more thing, looking at pre-deep learning literature is helpful too. For example, the temporal coherence of color was always used for tracking since decades ago.
🛠 Practical: 🖼 Image retrieval 🔗
Problems with repurposed classification network 🔗
- distorted input image
Models 🔗
alexnet-cls0imagenet-fc7alexnet-cls-lm-fc7
Benchmark 🔗
- Oxford 5k dataset
Cordelia Schmid: 📹 Action Recognition 🔗
INRIA Paris; IGCV, chair for CVPR; awarded prize for fundamental contributions to CV
Automatic video understanding 🔗
Data 🔗
- BBC dataset etc.
Evaluation 🔗
- TradVid video challenge
Possible outputs 🔗
- bounding boxes tracking people moving
- short captioning, e.g. “birthday party”, “grooming a cat”
- more holistically, a complete description/narrative of a picture
Challenges 🔗
- camera motion (cinematography)
- intra-class variation
- viewpoint changes (scene transitions?)
Why video? 🔗
Is the woman opening or closing the door? We need motion information; still images not sufficient
History 🔗
Johansson (1973) motion perception
Optical flow 🔗
Deriving a motion field from apparent motion of brightness patterns in the image.
Definition: Displacement of a point from frame t-1 to frame t.
Data 🔗
MPI sintel flow dataset
Assumptions 🔗
Projection of point is same
The luminosity of a point is the same across timeframes. Brightness constancy equation: \[l(x, y, t-1)= l(x + u(x, y), y + v(x, y), t)\]
Small motion
Points don’t suddenly jump large distances.
Spatial coherence
Points move like their neighbours.
- solve aperture problem, by Lucas-Kanade algorithm
- use neighbours in a matrix; similar to Harrris corner detector. \(M = A^T A\) is the second moment matrix.
Approaches 🔗
Horn & Schunck algorithm
Works well only for small displacement
Solution: Add a LDOF for large displacement
Matching term penalizing difference between flow and HOG (Histogram of oriented gradients) descriptor matches,
📑 FlowNet: CNN to estimate optical flow
It’s too difficult to manually annotate optical flow, and this CNN approach needs a lot of data. So a common workaround is to use a synthetic dataset with 3D graphic rendering.
FlyingThings3D dataset
How realistic does synthetic data need to look? -> It depends on the task.
Benchmark comparisons
- EpicFlow
- DeepFlow
- EPPM
- LDOF
Applications 🔗
- Video segmentation/tracking challenge
- Challenging when objects are close to camera; traditional approaches like 👀 RANSAC would also fail
- MP-Net
Conclusion 🔗
Smaller networks have same performance
- 📑 PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost
- 📑 LiteFlowNet: A Lightweight Convolutional Neural Network for…
We can also learn flow from 3d convolutions or static images
- 📑 im2flow
Action Recognition Task 1: Action Localization 🔗
Approaches 🔗
STIP; space-time interest points
Get discriminant of matrix
dense trajectories
📑 two-stream convolutional networks for action recognition in videos (Zisserman)
📑 learning spatiotemporal features with 3D convolutional networks
📑 action tubelet detector
Unsupervised Object Discovery and Tracking in Video Collections
Action Localization Datasets 🔗
- Very limited
Action Recognition Task 2: Action Classification 🔗
Nice AVA dataset 🔗
Atomic actions composed in a hierarchy
Categories of atomic actions
- pose of person (walk, run, jump)
- interactions with objects (drive, carry)
- human-human (talk to, hug, fight)
Human-action co-occurrence 🔗
- High correlation:
fighting&martial arts - Low correlation:
fighting&watch tv- Biased towards corpus haha, kids always fight in front of TV in real life but not in stock photos.
Failure modes (“trivial shortcuts”) 🔗
| actual action | predicted action |
|---|---|
| reaching out arm | “hand shake” |
| covering mouth | “smoking” |
| looking down | “writing” |
It seems like the network is making its prediction solely based on the global pose, which is not good enough.
📑 Actor-centric relation network (ACRN)
Note: I asked Cordelia for more information but this is pending patent and not published yet. Relational model for reasoning; pairwise relation between actions and objects Implemented as 1x1 convolutions.
📑 A flexible model for training action localization with varying levels of supervision (Cordelia Schmid) 🔗
- “People tracks” obtained by automatic detection + linking
- Divided into “Tracklets”
- Tracklet feature representation
- Optimization with block coordinate Frank-Wolfe algorithm
Action-detection model 🔗
Evaluation 🔗
50% Intersection over Union (IoU) threshold
Basically faster R-CNN 🔗
RGB resnet-50 to get embeddings of frames, and feed into region proposal network.
Conclusion 🔗
- Importance of dataset for evaluation; e.g. centre bias in action recognition video datasets
- Designing model to take into account spatial relations
Julien Mairal: 📊 Large-Scale Optimization for Machine Learning 🔗
Research Scientist @ Inria Grenoble, multiple research awards We spend a lot of our time minimizing a cost function. How do we do this on a large scale? E.g. for large recommender systems, with hundreds of terabytes of data.
Supervised learning 🔗
Labels are in… 🔗
| \([-1, 1]\) | binary |
|---|---|
| \(k\) | multiclass |
| \(\mathbb{R}\) | regression |
| \(\mathbb{R^n}\) | multivariate regression |
| any general set | structured prediction |
With linear models, logreg, SVM… 🔗
- Assume there’s a linear relation between \(y\) and \(x\) in \(\mathbb{R}^n\)
- \(L\) is often a convex loss function
- quadratic loss
- logistic regression loss (curve sloping down),
- hinged \(max(0, -wx)\)
With neural networks… 🔗
Finding optimal \(w\) involves minimizing a non-convex function.
e.g. AlexNet had 50M parameters
Challenges
- Getting statistical guarantees, e.g. stability and convergence
- Scaling
Not just supervised learning 🔗
- \(L\) is not a classification loss any more
- K-means, PCA, EM with mixture of Gaussians, matrix factorization, auto-encoders can all be explained with such a formulation
\[\frac{1}{n} \sum L(\hat y , y) + \omega(f)\], where \(\omega(f)\) is the regularization term.
Intro to statistical learning and gradient-based optimization 🔗
Setting 🔗
- Draw i.i.d. pairs \((x, y)\) from unknown distribution \(P\)
- Objective is to minimize, over all functions, expected risk
\[min (R(h) = E_{(x, y) \sim P} [L(y, h(x))])\]
Minimize over specific class of functions \(H\) only
\[min_{h \in H} (R(h) = E_{(x, y) \sim P} [L(y, h(x))])\]
Nesterov’s acceleration (momentum) 🔗
n-convex problems, can get stuck in saddle-point (flat region)
How does “acceleration” work?
No simple geometric explanation, but there are a few obvious facts and a mechanism introduced by Nesterov called “estimate sequence”
Obvious facts
- Simple gradient descent steps are “blind” to past iterations, based on a purely local model of the objctive
- Accelerated methods usually involve an extrapolation step
Stochastic optimization 🔗
Stochastic gradient descent algorithm
Minimizes expected risk (which is what we want), not empirical risk
How to be as cheap as SGD while enjoying fast (linear) convergence rate like gradient descent?
- SVRG, SAG/SAGA, SDCA, MISO, Finito
- FISTA
SVRG, etc. are better than FISTA if \[n \ge \sqrt{L/\mu}\]
Accelerated SVRG
Better than SVRG, if \(\frac{L}{\mu}\) is large (problem is badly conditioned).
❓Can we do better for large finite sums?
Variance-reduced stochastic gradient descent 🔗
Acceleration works in practice, but poorly understood.
Questions 🔗
Is there some theoretical optimal learning rate for neural networks like \(\frac{1}{L}\)? 🔗
In practice we just usually try some learning rate, divide by 10, try again, divide by 10… lol.
Jean Ponce: 🏫 Weakly Supervised and Unsupervised Methods for Image and Video Interpretation 🔗
Inria and NYU; set up research labs at MIT, Stanford, UIUC; “Pillar of PRAIRIE Institute’
Problem with human labels 🔗
Expensive 🔗
MS COCO: 2.5M labelled instances and 238K images of 91 object categories, all painstakingly outlined.
Subjective labelling 🔗
Why not delineate individual grass blades? Or the man’s hat?
Overview 🔗
Weaker forms of supervision 🔗
- image-level labels
- metadata
Semi-supervised 🔗
- only some data are labeled
Unsupervised 🔗
- self-supervised (as previously covered in Andrew Zisserman’s talk), akin “free” labels
- or, not. (without any ‘‘free” labels.)
❓learning can be done by predicting things about the world 🔗
Cosegmentation of images 🔗
📑 Discriminative clustering (DIFFRAC) (Xu 2004, Bach & Harchaoui 2007)
Optimization
- relax to continuous problem
- EM/block-coordinate descent
- quasi-Newton and projected descent for the two steps
- round up solution
What’s missing: 📑 foreground model (Rother et al 2006)
TV series come with metadata 🔗
📑 “Hello! My name is… Buffy” – Automatic Naming of Characters in TV Video
- align subtitles and scripts with dynamic programming algorithm
- extract face tracks from movie frames
- learn to identify which characters each face belongs to
Temporal localization as classification 🔗
temporal action localization
Frank-Wolfe algorithm
- replace cost surface by its tangent plane and minimize over Z
- Update Z
📑 learning from narrated instructional videos (Alayrac, CVPR 2016)
⭐️maybe do self-supervised learning using lecture videos? e.g. Kyunghyun explaining stuff on his slides input: instructional videos and text transcriptions output:
- sequence of main steps
- visual and textual models of the steps
- temporal localization of the steps
📑 how much supervision do we really need? (Cho, CVPR ‘15’)
📑 unsupervised feature learning (ICML 17)
- discriminative clustering with CNN; not by creating “free labels” like self-supervised learning
- optimize with coordinate descent, max max the loss
word2vec
analogies and relationships as “linear algebra” (paris = france + (berlin - germany))
- modeling contextual info with co-occurrence statisticsf
(Cho, kwak, Schmid, Ponce, 2015) 🔗
objects often co-occur with each other, union of horse and fence… 🔗
we don’t know how to model context
what is an object, part of an object, context… where to stop, where to start? ❓ 👀 how to talk about constituent parts of an object, and about you
ceveat: region proposals were supervised (cheating?)
matching model: probabilistic Hough matching 🔗
got pairs of images
build embeddings
simple iterative algo 🔗
- retrieve 10 nearest neighbous from some global descriptors (Olivia and Torralba 2006)
- Match
fed movie scripts from bourne identity, learns what a car is over 🔗
“the dog looks like the pig looks like meeee… I’ll skip on that one” 🔗
yann 🔗
graph transformer networks; the second part nobody read, complicated….
we need to remember the world is 3-dimenional 🔗
‼️ architectures need to go beyond pattern recognition ⭐️
Martial Hebert: 🤖 Robotics for Vision 🔗
progress in CV has not translated into progress for autonomous systems/robotics. why?
real world problems 🔗
📹 monocular drone flight through a dense forest; any failure on a single frame could have catastrophic results
- continuous perception
- real time
- budgeted decision (must have fast decision making)
- forced decision
unrecoverable failures
some papers coming out soon:
📑 Special issue on introspective methods for reliable autonomy 📑 Special issue on long term autonomy
vastly reductive overview of typical system 🔗
input -> perception box -> interpretation -> reasoning & decisionHowever, even if your perception and interpretation have 95% accuracy, this is still unacceptable in the real world. We need to be able to shortcut this pipeline.
introspection 🔗
Know when you don’t know. Evaluate whether the input (e.g. the visibility of the surroundings) is good enough to make a decision with.
input -> perception box -> interpretation -> reasoning & decision
| ^
|__________________________________________________|declaration rate
percentage of inputs for which you’re going to produce an output
- 100%: take decisions very often, with a lot of risk.
- 0%: super conservative, make a decision only on those inputs which you are super confident will have a good output.b
failure modes
explicitly define what to do in the event that the input is insufficient, e.g. if the input image results in poor trajectory evaluation
ROC curve on detection
why not just give the confidence score of the perception system? because the confidence score will often not be representative of the accuracy
best approach: 🔗
deliberative approach with
- introspection
- failure modes
poor metrics 🔗
do you care if your point cloud is 3mm or 1mm accurate? or if every pixel in semantic segmentation is correctly labeled? what’s more important is how good the planned trajectory is, or the high-level shapes of the segmentations.
multiple hypothesis 🔗
aka explainable predictions, structured uncertainty, …
perception box -> interpretationoutput multiple likely and diverse hypotheses.
| .*.
| .. . * ..*..
likelihood| . . ... . .
| . . . .. .. .. ..
| .. .. .. .. ... .. .......
| ...... .. ..
-----------------------------------------------------
perception outputalgorithm
similar to boosting searching a for modifying the energy function
multiple decision strategies 🔗
aka adaptive planning, dynamic control strategy, …
- have multiple reasoning boxes and to dynamically switch strategy
- can help with reusing planners (decision-making) across situations
reasoning & decisionexample technique
list prediction significantly reduces empirical risk:
Each predictor in a list focusses on different regions in the space of environments. This overcomes the shortcoming of a single predictor, and improves overall performance.
how to determine number of planners?
fixed, based more on computing resources
anytime prediction 🔗
output a crude early result, and continuously improve it until interruption
| Concept | Explanation |
|---|---|
| Interruptability | can give an answer at any time |
| Monotonicity | answers do not get worse over time |
| Diminishing Returns | initial improvements are more useful |
multiple models (assemble weak predictors/features)
cascade design and early exits
loss
dynamic adaptive loss, AdaLoss: give higher weight to blocks that are going to perform poorly
- again, similar to boosting
- good performance
conclusion 🔗
input filtering
objective error design
generating multiple hypotheses
adaptive planning
anytime prediction
Nicolas Mansard: 🏃 Humanoid Motion Planning 🔗
move like a human
problem formulation for end-to-end control 🔗
minimize preview cost of control sequence such that given
how to integrate knowledge of subproblems in robotics, in IA? 🔗
- many subproblems are well understood in robotics
- IA does not perform as well
Geometry 🔗
solve inverse geometry with…
nonlinear programming
- usually a non-convex problem
rigid-body kinematics
joint kinematics
Dynamics 🔗
Optimal control 🔗
Agile robots 🔗
Julien Perez: 📖 Machine Reading 🔗
multi documents answering, on Wikipedia 🔗
“Who invented neural networks?” “Lecun et. al.””
motivations 🔗
- human knowledge is mainly stored in language
applications 🔗
- collection of documents as knowledge base (KB)
- social media mining
- dialog understanding
- fact checking (fake news detection)
information extraction approaches 🔗
non-DL approach
components
reading machine
represents documents in structured data e.g. as subject-predicate object
reasoning machine
structured query e.g. in SQL, SPARQL… to ask a question about structured data
problems
- fixed/predefined ontologies
- fixed/predefined lexical domain
- data duplication by structuration
classic deep NLP approach
problems
- unnecessary requirements
- annotations
- priors
- not end-to-end- machine comprehension
- is language-dependant syntax a requirement to semantics/
- unnecessary requirements
machine reading tasks 🔗
The bAbI project: ALL THE TESTS!
reading comprehension datasets
- 📑 RACE
- MCTest
- 📑 The goldilocks principle: Reading Children’s Books
📑 Blunsom: Teaching Machines to read and Comprehend
losses
- linear regression loss
- pairwise loss
span selection
- SQuAD
- [[https://rajpurkar.github.io/mlx/qa-and-squad/][One defining characteristic of SQuAD is that the answers to all of the questions are
segments of text, or spans, in the passage.]]
- TriviaQA
- SQuAD
reasoning over knowledge extraction
- 📑 Weston: towards AI-complete question answering
Models of reading 🔗
building blocks
RNN’s
types:
one-to-one
many-to-many
popular models:
- LSTM
CNN
Understanding Convolutional Neural Networks for NLP advantage of being heavily parallelizable, vs sequential nature of RNN’s
- like n-grams
-
attention mechanism
pointer networks
wrt to a sequence, produce a sequence, but actually a pointer over the input
Retrieval models 🔗
Examples of extractive models
📑 text understanding with the attention sum reader network (2016)
encode the text, compute machine relevance, and compute
📑 Deep LSTM readers (NIPS 2015)
Blunsom: Teaching Machines to read and Comprehend
📑 R-net (2017)
- microsoft beijing
stacked
question-passage matching
transform representation of passage wrt question representatio
- attention-based RNN with additional gate to determine information of passage wrt a question
output layer - pointer network
performance
- sota when published in 2017 on SQuAD
- top 3 currently
📑 bidirectional attention flow for machine comprehension
slightly worse performance than R-net but interesting
📑 Google QANet
data augmentation with backtranslation
use beam search to produce paraphases
Error analysis for extractive models
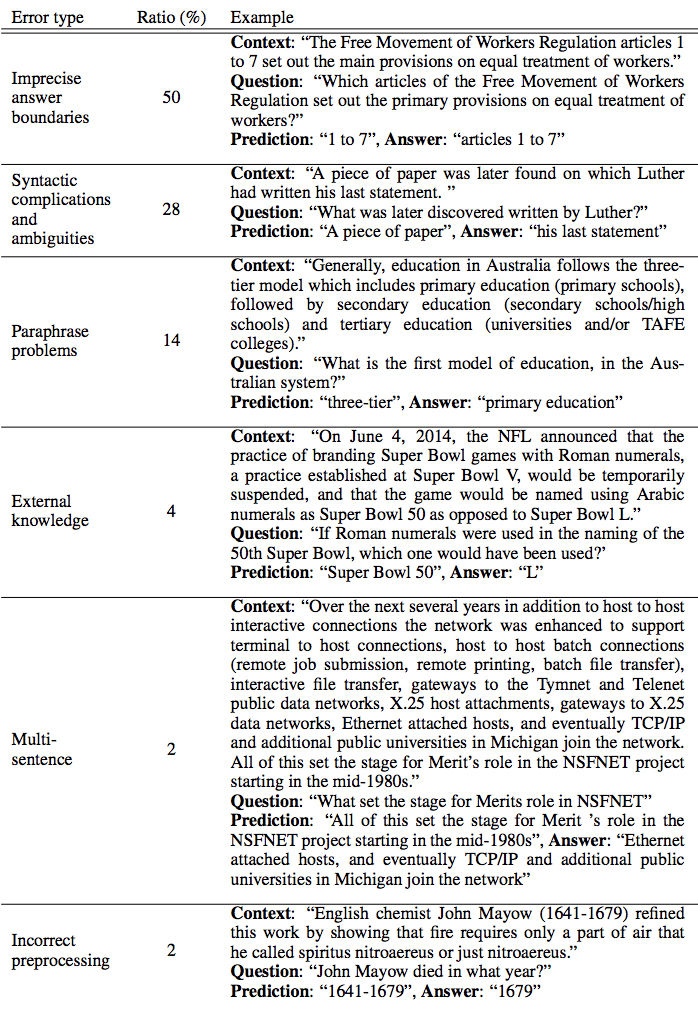
reasoning models
📑 towards AI-complete question answering
reasoning over knowledge extraction
- convert textual information into interpretable structured knowledge
categorical cross-entropy loss
sidenote
sometimes people replace english words with arbitrary tokens to ensure the model is answering based on the text and not on prior knowledge, e.g. semantic information from word embeddings
end-to-end memory networks
models seem to be getting more complex
- context
- priors
- position
- autoregressive models
- non-commutative models
applications 🔗
dialog state tracking
modularity is the current approach
- divide and conquer
- handcrafted models; case-by-case adaptatin
- annotation required
e.g. Alexa,
⭐️ end-to-end opportunities
- the third dialog state tracking challenge
SOTA
generative
- HMM
discriminative
open challenges
- longer context
- looser supervision
- reasoning capability
- minimize intermediary steps
- fixed ontology
- fixed KB
end-to-end memory network
controller + memory module 📑 dialog state tracking: a machine reading approach to using deep memory networks (Perez, 2017)
fact checking
fact checking as stance detection
📑 neural stance detectors for fake news challenge nn
many challenges
- hard to collect labeled data
- little and imbalanced data (why not use multi-task?)
- explainable decisions are often needed
open questions 🔗
- 📑 reading wikipedia to answer open-domain questions (2017)
-
Emmanuel Dupoux: 👄 Speech and Natural Language Processing 🔗
currently at DeepMind cognitive machine learning team, also INRIA
duplex 🔗
- pauses to sound ‘natural’
- filler sounds like “uh”, “um”
levels of meaning 🔗
-insert photo here-
4 challenges 🔗
language diversity
not just 🇬🇧 english
phonological diversity (vowel-consonant composition, etc.)
morphological diversity (one word, usually one meaning)
- agglutinative
- fusional
- …
syntactic diversity
- constrained word order (english, french)
- free-er word order (polish; 8 ways to say the same thing)
- super free word order
semantic diversity
words fuzzily partition the semantic space. different languages have different partitions.
variability
phonetic and phonological variation
language changes across the country; e.g. “do you pronounce the ‘r’ in ‘arm’?”
ambiguity
lexical ambiguity (homonymy)
English: weather, wether, whether French: vers, verre, ver, vert, vair
semantic ambiguity
many people named Michael Jordan
multiple ambiguities in practice
“I made her duck”
- I threw something at her, and made her duck?
- I made her (plaster?) duck
- I made her a cooked dish of duck
- …
sparsity (long tail of exceptions)
power law, everywhere
possible solutions 🔗
diversity (between languages)
- more data (e.g. bible lol)
problem: diminishing returns of gathering more data (7000 other languages not covered by Google)
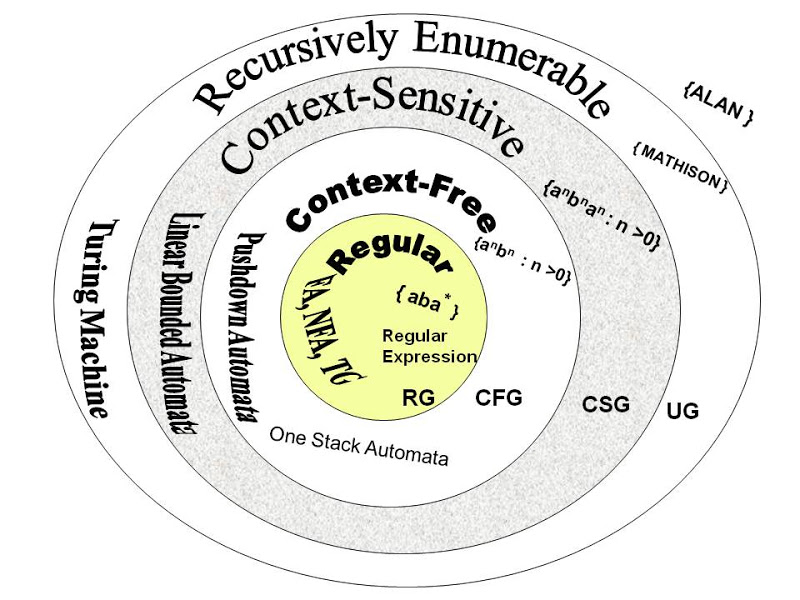
- explicit linguistic theories (universal grammar)
problem: hand coding
- Chomsky hierarchy of grammars, (Miller & Chomsky, 1963)
- constrained learning architectures
- probabilistic phrase structure grammar, non parametric bayesian models, stack DNN, etc.
other suggestions:
- use intermediary representations like MNT
- use the bible as training corpuses, in all languages
- train embeddings separately
variability (within same language)
- More data
minor problem: catastrophic interference, of forgetting old data problem: diminishing returns
- Domain adaptation
transfer learning e.g. GAN’s for transfer learning
- Augment data with little variations; synthesize dialects
ambiguity
- ignore and train end-to-end
problem: you’re averaging all the variants, resulting in blurring/mode collapse
- probabilistic architecture (learning distributions)
problem: more difficult
other suggestions:
- having context to infer meaning from
- database of explanations of all the senses of the word, and data of context
- planning into the future until the ambiguity disappears
sparsity
on a case-by-case basis
episodic basis
putting this in practice: deconstructing HAL 🔗
speech recognition (ASR) -> Acoustic modeling ->Speech Recognition (ASR)
problem: Heaps’ Law: # words grows as corpus grows
you can’t build a lexicon for the language; lexicon is infinite solution: break down into subproblems
problem: ambiguity
solution: probabilistic framework
P(W|X) ~ P(W|X) P(W) ~ acoustic model * language modelfind word sequence
Wthat maximizes posteriorP(W|X)- phase 1: acoustic modeling
vowels: height [a/e], roundness [i/y], front/back [o/e]
- speech feature extraction: MFCC pipeline
average frequency bands with triangular windows that are increasing as you go up frequency ==> obtain a mel spectogrammel spectogram
people used to do a discrete cosine transform
⚠️ ambiguity
what about languages with tone (e.g. Mandarin)? or with contrastive stress? (Spanish) ❎ in mel averaging you lose the frequency (tone) information
- ⚠️ diversity
Acoustic Modeling
Multi-state HMM’s
model phoneme by sequence of mixtures
⚠️ variability
dialects, foreign accent, children, speech defects, whispered speech, angry speech… and permutations of all the above (an angry child with a foreign accent and speech defect)
humans are very good at this
- the wicked witch of the west -> (the weckup wetch of the wast)
- after 20 min, wetch is a word for people
funny video showing scottish accents failing at voice recognition
human vs machine learning
unsupervised learning (sensory) supervised learning (orthographically encoded)
summing up 🔗
language is complex
4 challenges
useful to remember how humans do it
Kyunghyun Cho: 🌏 Machine Translation 🔗
NYU and Research Scientist at FAIR; PhD at Aalto and Postdoc at Montreal Best-known for work on statistical neural machine translation.
💬 “Two-thirds of what I wanted to cover has been covered already… So I decided, let’s revamp all the slides, make it fun, and also try to cover the latest research.”
History 🔗
Hierarchical structure by Borr 🔗
borr hovy levin morphological analysis world structure
Rosenblatt (1962) 🔗
Allen (1987) 🔗
rudimentary CNN
Chrisman (1992) 🔗
Modern neural translation 🔗
Schwenk (2004), …. Replace all the Statistical machine translation (SMT) with just a neural network
how do we represent a token? 🔗
how do we use neural net? we apply an 👀 affine transform, a nonlinearity, stack them, and hope that more will result in better representation, right? “we don’t need to know anything about language to do NLP”
Language modelling 🔗
Captures the distribution over all possible sentences.
- Input: sentence
- Output: probability of input sentence
\[p(X) = p((x_1 , x_2, …, x_T)) = p(x_1)p(x_2|x_1) … p(x_T|x_1, x_2, …, x_{T-1})\] #+END_SRC
autoregressive language modelling 🔗
each conditional is a sentence classifier the distribution over the next token is based on all the previous tokens
- This is (the negative of) what NLLLoss computes
count-based n-gram language models 🔗
estimate with MLE (# heads)/(# coin tosses)
estimate n-gram probabilities
P(“NYU”) = count(“NYU”) / count(“NY*”)
problems
data sparsity; lack of generalization
nobody every chases a llama! “p(llama|chasing a) = 0”
inability to capture long-term dependencies (beyond n tokens)
neural n-gram language model 🔗
infinite context recurrent language models (Mikolov, 2010) 🔗
validation
always test from the future or models will find loopholes and be unable to generalize
conclusion 🔗
- autoregressive, infinite context, with self-attention/dilated convolution
- extract sentence representation
- put it all together for NMT
NMT 🔗
use autoregressive language model as a decoder
RNN NMT 🔗
this model is super general and decoupled from language; can be used for image captioning, speech recognition… in production, you need to do much more that’s very engineered towards translation itself, e.g. choosing the correct gender pronoun (done manually as post-processing or cleanup) checking whether a sentence is grammatical or not is an unsolved problem… so far the analyses are limited (but spellchecker is often used as post-processing step) 💬 “i have 18 minutes and like 80 slides” 😂
practice 🔗
check out Nematus, OpenNMT, FairSeq…z 🔗
NMT is coined by “Yours truly” at a poster in 2014
decoding from a recurrent language model 🔗
beam search is defacto standard 🔗
⭐️ “learning to decode” 🔗
- something Kyunghyun is pursuing
neural network = forgetting machine
CNN classifying panda;
- throw away background and leave foreground
- segment to extract panda from foreground
- segment face and throw away body
- yes panda or no panda
do the same thing for text
view the entire RNN a an environment in which we can define a reinforcement learning problem
RL
- policy gradients
- REINFORCE algorithm
and you get simultaneous translation
- inspired by simultaneous interpretation from nurenberg trials, so many war criminals,
- source words arrive one at a time
- no data for this, only large enough/sufficient for evaluation and not training
multilingual translaion for low-resource languages 🔗
for universal encoder/decoders, the models became able to handle mid-sentence code-switching
limitations 🔗
tricky when availability of data drastically differs
will overfit on low resource pairs while not learning anything about large resource becomes more of an art than a science, to schedule the learning
transfer learning
tricky to retrain a subset of parameters for a new language pair
- no clear winning strategy, differs based on source language etc
model-agnostic meta-learning MAML (FInn, 2018) 🔗
multi-task learning starts to overfit to sourcetask 🔗
with metalearning it never overfits to source task 🔗
metalearning has lots of benefits in MNT and RL 🔗
- ⭐️ gradual shift to higher-order learning;
- learning to optimize… -
Leon Bottou: Artificial Intelligence Unsupervised Learning and Causation 🔗
what works? 🔗
Image recognition, MNT, RL in games
what doesn’t work? 🔗
training demands too much data 🔗
playing atari games… after playing more games than any teenager can endure playing go… after playing more games than any grandmaster has played (actually, all of mankind 😂)
the statistical problem is only a proxy 🔗
e.g. “giving a phone call” according to photos on the Internet is something that just happens when a :man_dancing_tone3: person is near a ☎️ phone. So our statistical models are completely missing the concept of “giving a phone call”
structure does not help 🔗
2 studies from stanford in 2016; one with bigrams and one with recursive parsing tree; replace parse tree with random structure worked just as well
entropy
entropy = negative log likelihood entropy of english sentence is between 0.6 and 1.3 bits
what is structure for?
to help construct new sentences, rather than to understand existing sentences gonghedang bu ru minzhudang minzhudang bu ru gonghedang after a patch… LOL 😂 hardcoded “democrat party better than republican party”
causation 🔗
relation between causation and unsupervised learning
causation and statistics 🔗
what is causation? 🔗
Rubin school
potential outcomes
Pearl school
causal graphs and do-calculus
others
- statisticians: spirtes, richardson, robins
- physicists
- philosophers
- at least 7 partially incompatible definitions of causation 😂
manipulations 🔗
causation can be inferred from the outcome of manipulations e.g. ☔️ if we ban all umbrellas, will rain stop?
Reichenbach’s principle 🔗
snake oil
those with sloppy lifestyles were less likely to try and more likely to get better’ this is called the Simpson effect.
penicillin
counterfactual estimate
contextual bandit
causal intuition
c X --> Y a \ / b v v ZX has a negative effect on Y; both X and Y have positive effects on Z -scatterplot for Z=0 and Z=1- mean and covariance reveal a wrong causal effect! that X and Y are positively correlated
how to build unsupervised learning machine that gets causal intuitions? 🔗
- observations can lead to causal intuitions
- we can apply scientific method
causal direction 🔗
footprint example 2 🔗
a hint that X causes Y (?) (there’s a peak in Y when X is flat???)
featurizing a scatterplot 🔗
because high moments give hints
- using a neural causation classifier (NCC)
achieved 80% accuracy on synthetic Tuebingen dataset
counterfactual on images 🔗
- how would the image look like without cars
- how about without the bridge (and with cars)?
proxy variables and shadow footprints 🔗
a wheel and a car
object features and context features 🔗
- object features are inside bounding box, e.g. car wheels
- context features are outside, e.g. shadow or road below car
note: to CNN’s, cars are only on grass, not on beach
unsupservised learning 🔗
yann’s 🍰 cake
the affordance of an object is
- what can i do with it?
- what can others do with it?
- what will be the result?
discovering affordances entails discovering causal mechanisms 🔗
simple models for a complex world 🔗
case in point: children drawings but our models are highly complex models
comparing distributions 🔗
- Total Variation (TV) distance
- KL divergence
Jensen-Shannon (JS) divergence
Earth-Mover (EM) distance or Wasserstein-1
GAN was shown to be equivalent to JS distance?!
- importance of distance measure in GAN
take distance with the right property to get the right behaviour
- had to train
f(as the critic in actor-critic) aggressively in WGAN
surprise/energy 🔗
- energy distance = maximum mean discrepancy (MMD)
- something about Hilbert space
WD vs MMD 🔗
statistically very different 🔗
WD has catastrophic complexity as dimensions increase -insert photo here-
BUT IN practice…. 🔗
MMD training of high dim got stuck WD of same high dim implicit models were good
conclusion 🔗
- need to look at geometry to discover what kind of distance in causation
- stats != semantics
- how to manipulate statistical proxy to learn what u want
- causation seems to play a central role
- even static image datasets hint about causal relations (experimental results)
- using right probability distances could help (theoretical and experimental results)
Rémi Munos: Off-Policy Deep Reinforcement Learning 🔗
Senior Researcher @ DeepMind Paris
:shallow_pan_of_food: Ingredients of satisfying research 🔗
(this rarely happens)
need 🔗
- limitations/core problems of current approaches
idea 🔗
benefit 🔗
- theoretical analysis
Retrace(λ): 📑 Off-Policy Deep Reinforcement Learning (Munos, 2016) 🔗
Need 🔗
- limitations of DQN and A3C
Idea 🔗
- retrace algorithm: truncated importance sampling while preserving contraction property of Bellman equation
Advantages 🔗
- Convergence to optimal policy in finite state spaces
Algorithms similar to Retrace and A3C: ACER, Reactor (Retrace-actor), MPO, IMPALA
📑 IMPALA (2018)
👍 gains in performance and efficiency
- Heavily distributed architecture with multiple Actors having a CPU each and learner on a GPU

Reinforcement learning 🔗
Value-based 🔗
Bellman (1957) + DP produce a policy to maximize sum of future rewards
- value function Q of policy pi
expected sum of future rewards
- Optimal policy
choose action that maximizes the Q-values
argmax_a Q*(x, a)represent Q with a neural network
problems
- moving target; target changes as Q changes
- data is not i.i.d., but sampled while moving along a trajectory
DQN
be closer to supervised learning
properties
- 👍 off-policy
- sample efficient
- allows any exploration strategy
- ❌ 1-step 👣 bootstrapping (only looks 1 step into the future?)
- slow to propagate information
- accumulates errors
- no RNN’s since LSTM needs backprop through time
- 👍 off-policy
dissociate acting from learning
store actions in a memory replay and learn from memory
fix target network for a while
Policy-based 🔗
Pontryagin’s maximum principle (1956) optimize expected discounted sum of future rewards via gradient ascent
problems
high variance estimate
async Actor-critic algorithm (A3C)
learn state-value function
V(x)instead ofQ(x, a)using n-step Temporal Difference (TD)properties
- ❌ on-policy
- not sample efficient; no memory replay
- no complicated exploration strategies
- 👍n-step 👣 bootstrapping
- faster than DQN
- can possibly use RNN to learn from sequences
- Doom (2015) used LSTM and DQN
- ❌ on-policy
Off-policy RL 🔗
behaviour policy mu(a|x), target policy pi(a|x)
credit assignment problem 🔗
use importance sampling to re-weight the TD (temporal difference) of the target policy over the old policy trajectory (behaviour policy) 👍 unbiased estimate of Q^pi ❌ large (possibly infinite) variance
\(Q^\pi(\lambda)\) algorithm
\[ \delta Q(x, a) = (\gamma \lambda)^t \delta_t \] if pi and mu are (very) close, works!
comparison in terms of trace coefficients c_s 🔗

caveat 🔗
still, all of these algorithms fail on games with little feedback/reward, cannot encode long-term dependencies
V-trace 🔗
Similar to Retrace, but learning state-value function \(V\) instead of a state-action-value function \(Q\). Introduced in 📑 IMPALA (2018)
🛠 Practical: 🛒 Reinforcement Learning by Criteo 🔗
Hugo Larochelle: Generalizing From Few Examples with Meta-Learning 🔗
Google Brain, few-shot learning
Exploit alternative data that is imperfect but plentiful 🔗
| data | type of learning |
|---|---|
| unlabeled data | unsupervised learning |
| multimodal data | multimodal learning |
| multidomain data | transfer learning, domain adaptation |
Unseen classes in multidomain data 🔗
Machines are getting better at it 🔗
📑 Human-level concept learning through probabilistic program induction Generating new (unseen) characters
Meta-learning 🔗
A pretty old topic dating back to Schmidhuber’s “Learning to learn” and neural networks that learn to modify their own weights.
📑 Learning to learn by gradient descent by gradient descent
Train an optimizer that would output an update for all the parameters of the model -> kind of learn an alternative to SGD, Adam etc.
gradient descent is a differentiable, recursive operation
find sequence of learning rates such that the final neural network has the best performance on the validation set
What is meta-learning? 🔗
Learning to generalize; evaluate on never-seen problems/dataset
Components 🔗
Data
Usually Mini-ImageNet
Learning algorithm
Output is learned
M- Each episode has a new learner produced by the meta-learning episode
Meta-learning algorithm
Input is D_train-D_test pairs of episodes: 2 datasets of training and test sets (where test contains unseen classes) Output is meta-learner
AObjective is good performance on test set
-
sequentially fit gaussian process
multi-task bayesian algorithms; transfer model selection between different problems
Larochelle: coming up with a fixed learning algorithm
⭐️ a meta-learner that picks different modules depending on the dataset
📑 Matching networks for one shot learning (2016) 🔗
📑 Prototypical Networks for Few-shot learning (2017) 🔗
Use same embedding function f for test and training set
Prototypal class k
👀 If you’re using Gaussian it will be Euclidean distance? Equivalent to training an embedding such that a Gaussian classifier would work well.
- If you use more classes for the training episodes, you get better results.
⭐️ suggests there’s room for improvement in generating episodes
📑 Optimization as a Model for Few-shot learning (2017) 🔗
Using an LSTM-esque meta-learner to update parameters
- Feeding gradient of parameters wrt loss into the forget and input gates
- Minibatch of LSTM is size of # of parameters
📑 MAML for Dast Adaptation of Deep Networks (Finn, 2017) 🔗
Can start with this rather than meta-learner LSTM
Bias transformation 🔗
⭐️ there’s a hierarchical bayes interpretation of MAML’s 1 gradient descent update; from Berkeley as well
📑 SNAIL (Mishra) 🔗
Cold-start item recommendation (a meta-learning perspective) 🔗
low-shot learning from imaginary Data (2018) 🔗
areas of improvement 🔗
- class distribution within episode -
Lourdes Agapito: 💀 Deep learning for 3D human pose estimation 🔗
UCL?
Capturing 3D dynamic scenes 🔗
problems:
- unsupervised non-rigid surface reconstruction
- 3d human pose estimation from image
- dynamic and semantic segmentation
challenges 🔗
- little ground truth/annotated data
Approaches for 3D human pose estimation from image 🔗
direct regression with CNN 🔗
- 👍 bypasses the 2D pose estimation and 2D-to-3D lifting algorithm steps
- ❌ you need dataset directly from image to 3d pose (only one exists: human 3.6M dataset)
pipeline 🔗
- ❌ relies on 2 steps, so error accumulates
- 👍there are reliable 2D pose estimation and 2D-to-3D lifting algorithms
📑 Convolutional Pose Machines (2016) 🔗
📑 PPCA by Lourdes Agapito 🔗
image -> heatmap -> joint identification ->predicted belief maps->3D lifting->project back to 2D belief maps
loss on fused predicted belief maps and projected belief map
extensions
- using human-object interactions to learn more about the world/objects in the world
📑 Direct, Dense, and Deformable: Template-Based Non-Rigid 3D Reconstruction from RGB Video 🔗
- Total Variation (TV) regularization; vertices move similar to how neighbours are moving
- Preserve rigidity -> means preserving details
- with photometric cost, tracking fails; some shading details are lost
- need to model reflectance function correctly, to be robust to changes in illumination and capture high frequency information!
Synthesia 🔗
tracking face with 3d models instead of vertices; can modify the parameters and re-synthesize the faces
voice dubbing! 🔗
3D scene understanding 🔗
Mask-RCNN is performing really well, on 80 categories from the COCO dataset
📑 Mask Fusion (2018) 🔗
picture
 SLAM method
SLAM method- adding temporal consistency constraint
- assigning labels to detected objects
📑 scannet (2017)
community initiative to 3d map rooms with Bundlefusion, kinectfusion
Dynamic SLAM
Traditional SLAM fails on dynamic scenes
doesn’t detect a moving box on a conveyor belt at all
📑 Lourdes’ Dynamic RGB-D SLAM system
camera includes depth (the D in RGB-D)
can mask out people!
will be presented in October!
Conclusions 🔗
- deep learning for 3d vision is still in its infancy
- using 2d labels for 3d tasks is powerful
- ⭐️ lots of opportunity for self-supervised learning! multiple views of 3d model should agree on the 3d model
- we should emphasize on real-world applications of research to robotics etc., robustness to failure
🛠 Practical: 🔥 PyTorch Practical Session by FAIR 🔗
Conducted by Francisco Massa
Tensor (ndarray) library 🔗
np.ndarray <=> torch.Tensor
Automatic differentiation engine 🔗
computation done on-the-fly 🔗
- can use python primitives e.g. for-loops
gradients by automatic backpropagation through the graph 🔗
- higher-order gradients
- multi-device graphs
debugging 🔗
most famous debugger:
print()and more
☁ Themes 🔗
self-supervised 🔗
meta-learning 🔗
GANs 🔗
Last part of this Computerphile video 🔗
Generator learns a latent space of “cat pictures” such that if you smoothly move around this space you get smoothly varying cat pictures. Then you can do cool vector arithmetic in this space, e.g. black cat minus black plus white equals white cat?
RL 🔗
💡Miscellaneous Learnings 🔗
teacher student 🔗
Knowledge distillation is a potential solution for model compression. The idea is to make a small student network imitate the target of a large teacher network, then the student network can be competitive to the teacher one. github README with a nice description