Slides are available here, made from the same org file that this Hugo blogpost was generated from.
Motivating the Rules of the Game for Adversarial Example Research 🔗
Justin Gilmer, Ryan P. Adams, Ian Goodfellow, David Andersen, George E. Dahl (July 2018)
Presented by Christabella Irwanto
Goals of the paper 🔗
- Taking a step back and evaluating the relevance of adversarial ML in the real world
- Adversarial example defense papers mostly consider abstract, toy games that do not relate to any specific security concern
- Lacking precise threat models important in security
Background and definitions 🔗
- “Perturbation defense” literature: motivated by security concerns and proposing defenses against unrealistically-restricted perturbations
- Adversarial example = restricted perturbation of a correct example
- Assume “perceptibility” of perturbations is a security risk
- Started by Szegedy’s “Intriguing properties of neural networks”
- Adversarial example: an input to a machine learning model intentionally designed to cause the model to make a mistake (Goodfellow et al. [1])
- The example itself could be anything
…and not motivated by generalization performance or biological mimicry, rather than security
Key contributions 🔑 🔗
- Establish taxonomy of plausible adversary models
- Place recent literature within the taxonomy
- Recommend a path forward for future work
- Clearly articulate threat model
- More meaningful evaluation
Possible rules of the game 🔗
To study security, we need a threat model that is
- well defined
- clearly stated
- inspired by realistic systems
Goals of the attacker 🔗
- Targeted attack
- Induce a specific error, e.g. 🐱 ➡ 🐶
- Untargeted attack
- Induce any error, e.g. 🐱 ➡ 🐶 / 🐼 / 🦁 / 🐷 ❓
Knowledge of the attacker 🔗
- 🐵 “Whitebox”
- Full knowledge of model internals and training data
- 🙈 “Blackbox” query access
- System details are unknown but it can be queried
- ❓Partial knowledge
- Between the two extremes
Who goes first, and is the game repeated? 🔗
- Defense strategies:
- “Reactive”: defender can adapt to current attacks
- “Proactive”: defender must anticipate the all potential attack distributions
- In current literature, generally defender goes first and must be proactive
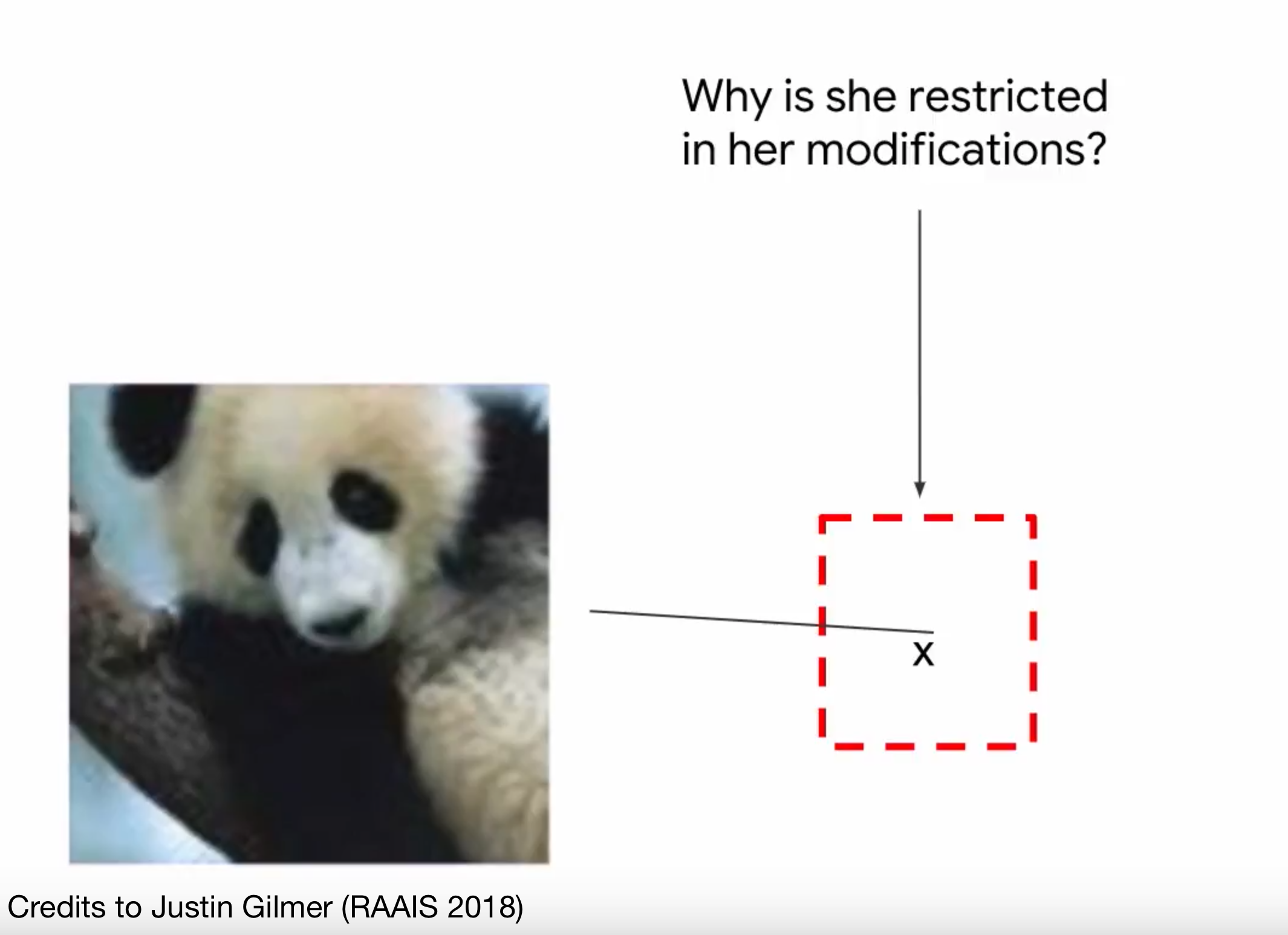
Action space of the attacker 🔗
What are they allowed to do?
Action space of the attacker 🔗
Can they do this instead?
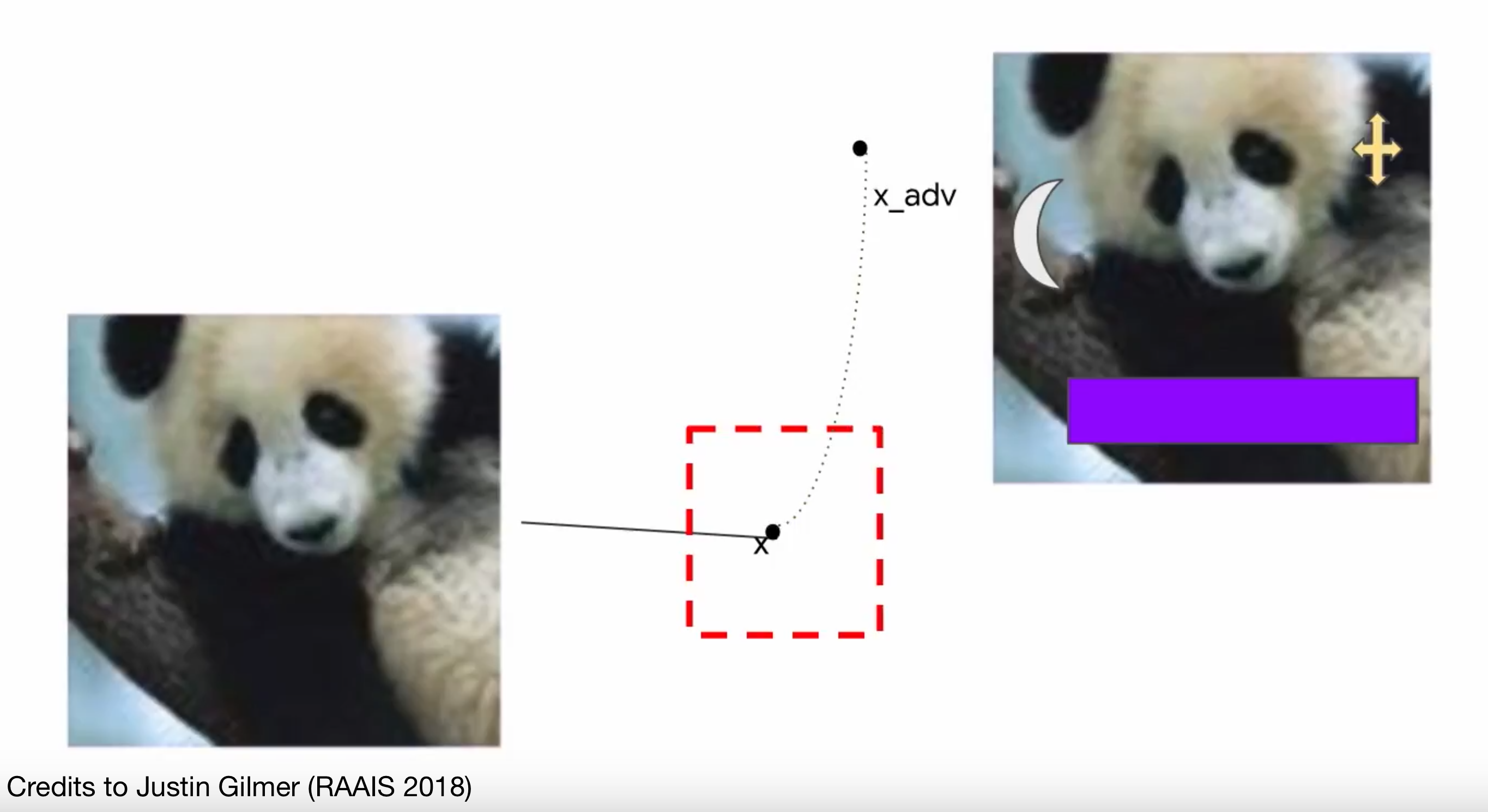
Action space of the attacker 🔗
Can they pick their own starting point?

Action spaces 🔗
| Security setting | Constraints on input (human perception) | Starting point |
|---|---|---|
| Indistinguishable perturbation | Changes must be undetectable | Fixed |
| Content-preserving perturbation | Change must preserve content | Fixed |
| Non-suspicious input | Input must look real | Any input |
| Content-constrained input | Input must preserve content or function | Any input |
| Unconstrained | Any | Any |
Content-constrained input 🔗
- Any input \(X\) with desired content or payload
- E.g. image spam can start from anything as long as it delivers an advertisement, and evades machine detection (untargeted attack)
- Repeated game
- Other examples: malware, content trolling
Non-suspicious input 🔗
- Any \(X\) that would appear to a human to be real
- E.g. “Voice assistant attack”
- Perturb white noise/music etc. to be interpreted as a command (Carlini et al. [83])

Unconstrained input 🔗
- Any \(X\) with no constraints whatsoever
- E.g. “voice assistant” scenario variations, iPhone FaceID unlock
 https://wired.com/story/hackers-say-broke-face-id-security/
https://wired.com/story/hackers-say-broke-face-id-security/
Content-preserving perturbation 🔗
- Perturb a particular \(X\) in a way that preserves content
- The space of content-preserving perturbations:
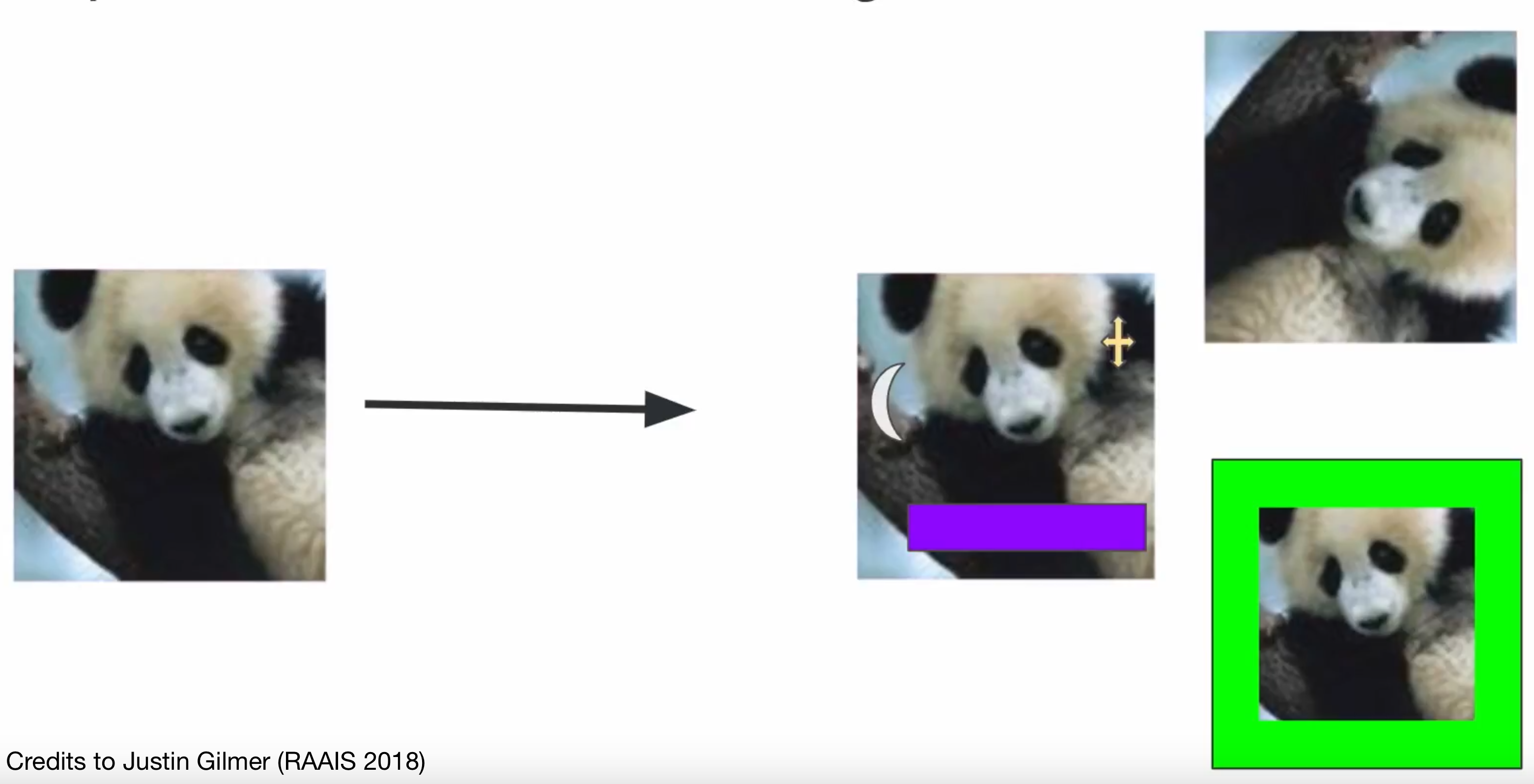
Content-preserving perturbation 🔗
- E.g. “pay-per-view” attack
- Perturb video to evade detection, but preserve content
- Viewers will tolerate huge perturbations

Imperceptible perturbation 🔗
- Perturb a particular \(X\) in a way that is imperceptible to a human
- E.g. ??? 404
- Imperceptibility can help with deniability, or longer evasion of detection, but it is not required
- Makes large assumptions about the attacker
- Robustness metric was not intended to be a realistic threat model, but as a toy game
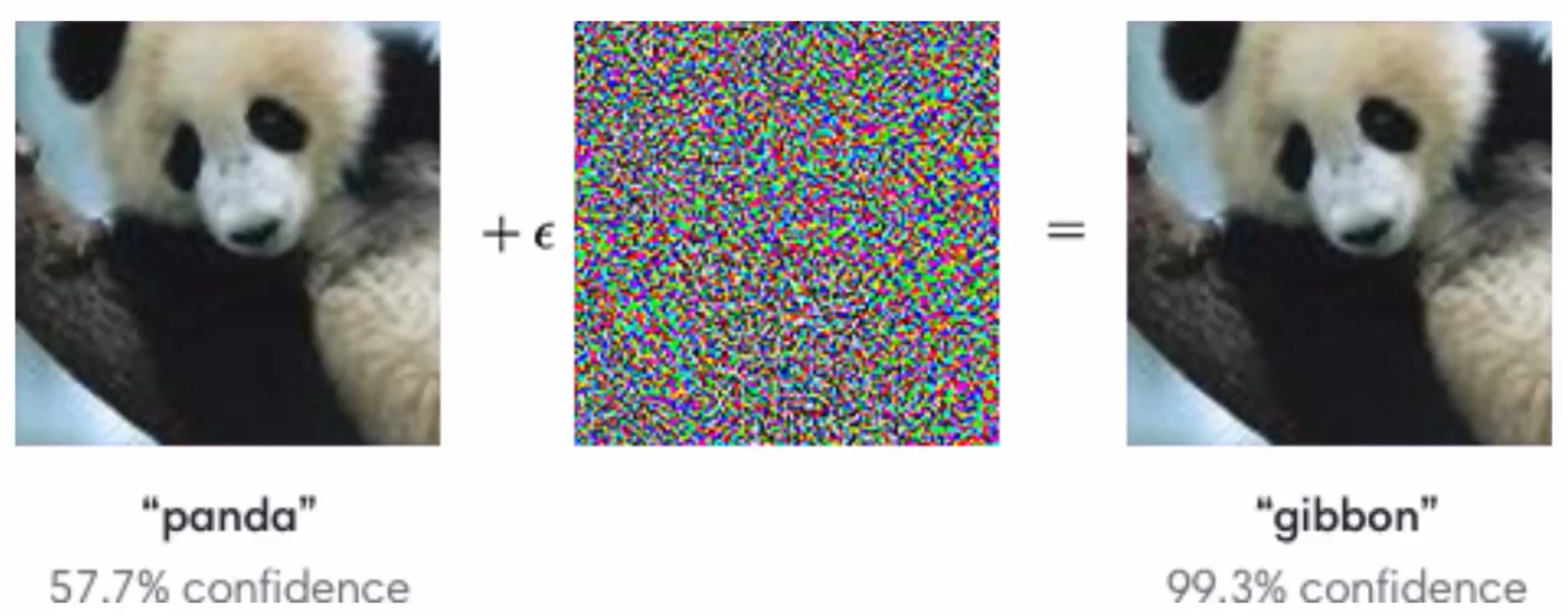
Recent literature 🔗
- Most perturbation defense papers surveyed assume
- Fixed initial sample drawn from data distribution
- Sample can be perturbed with \(l_p\) norm \(< \epsilon\)
- Often unclear if defense is proactive or reactive
Optimization problem to find worst case perturbation \(\displaystyle \delta_{adv} = \arg\max_{\substack{||\delta||_p < \epsilon}} L(x + \delta, y)\)
Evaluation metric is “adversarial robustness”, \(\mathbb{E}_{(x, y)\sim p(x, y)} [\mathbb{1}(f(x+\delta_{adv}) \neq y)]\)
- \(f(x)\) is model’s prediction on \(x\), and \(y\) is \(x\)’s true label
- Probability that a random \(x\) is with distance \(\epsilon\) of a misclassified sample
probability that a random \(x\) is with distance \(\epsilon\) of a misclassified sample
Problems with measuring robustness 🔗
- Evaluating \(l_p\) robustness is NP-hard
- Frequent cycles of falsification


Robustness is a misleading metric 🔗
Suspicious adversarial defenses
- Hardness inversion: robustness against a more powerful attacker (e.g. whitebox/untargeted) is higher than weaker attacker (e.g. blackbox/targeted)
- Symptom of incomplete evaluation, e.g. stuck in local optimum/gradient masking
Where does it fit in the taxonomy? 🔗
- Closest fit for current literature is in indistinguishable perturbation ruleset
- Standard ruleset is weakly motivated
- Does not fit perfectly in the taxonomy of realistic rulesets
- Even if we take the spirit of the literature’s ruleset…
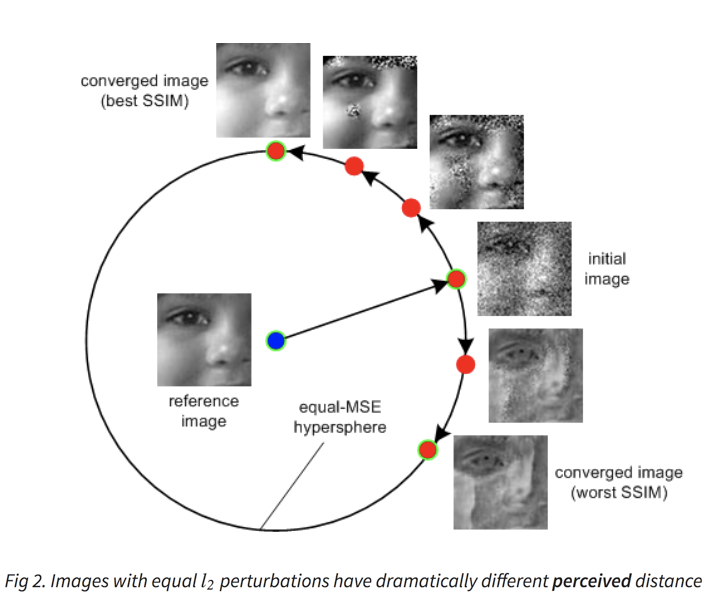
\(l_p \neq\) perceived similarity 🔗
- \(l_p\) is not even a good approximation for what humans see
- E.g. 1 pixel translation of image: imperceptible but huge \(l_p\) norm
- Depends on psychometric factors
- Given time to make decision? Motivated to look closely?
Plausibility of examples in literature 🔗
If security is the motivation, we should
- Study the most realistic ruleset
- Consider real-world threats
Let’s look at common motivating scenarios for the standard ruleset in the literature
Stop Sign Attack 🔗
- “Adversarial street sign” to fool self-driving cars
- Imperceptible perturbations are not strictly required
- High-effort compared to…

Knocked-over Stop Sign Attack 🔗
… simply covering sign, or knocking it over

Figure 3: “knocked over stop sign attack” is 100% successful in “tricking” the model, robust to lighting and perspective changes, and even worse, already occurs “in the wild”!
Evading Malware Detection 🔗
- Restricted \(l_0\) changes to malware binary’s feature vector
- Fits in the content-constrained input ruleset, but not in the standard ruleset
- Why would malware authors restrict themselves?
- Vast space of code alterations preserving essential functionality
Fooling Facial Recognition 👓 🔗
- Compelling only for weaker attacker action space constraints than the standard rules
- “Accessorize to a crime” (Sharif et al.) considers attacker impersonating someone to enter restricted area
- Glasses would fool face recognition system
- But… high quality prosthetic disguise would fool both human guards and face recognition system
Test Set Attack 🔗
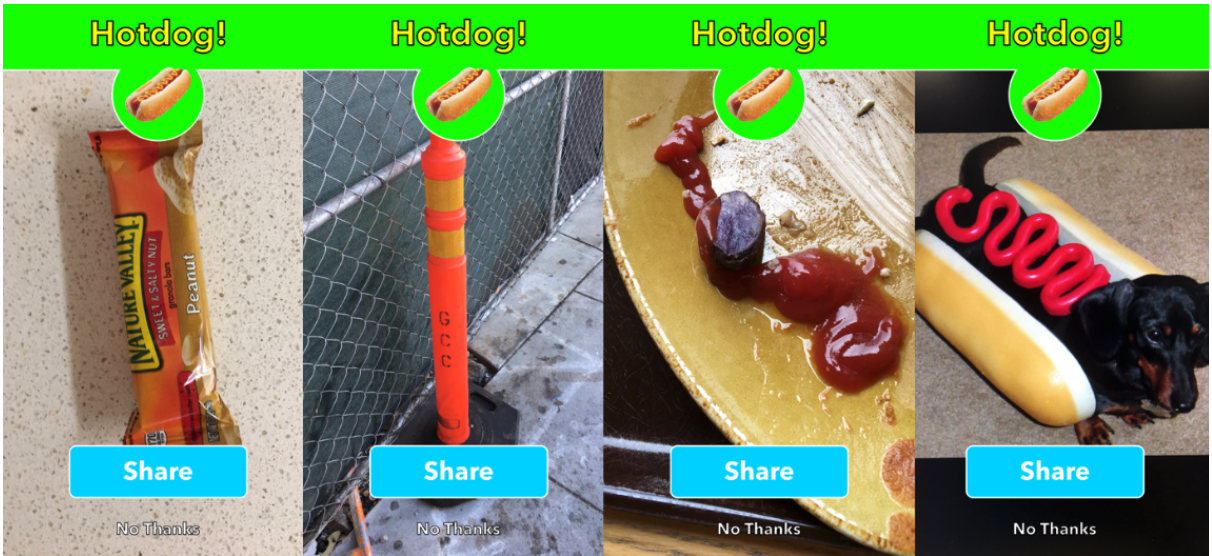
- Litmus test: pray some random \(x\) will be misclassified, i.e. the naïve adversarial example
- Non-zero error rate on test set \(\implies\) vulnerability to test set attack \(\implies\) existence of adversarial examples
- Many existing defenses increase test error
- Variation: randomly perturbing an image, also effective in inducing errors [107]
Evaluating errors realistically 🔗
- Researchers should attempt to approximate actual deployment conditions
- E.g. How prevalent is the adversary’s presence?
- Balancing accuracy on IID test set vs. on adversarial examples
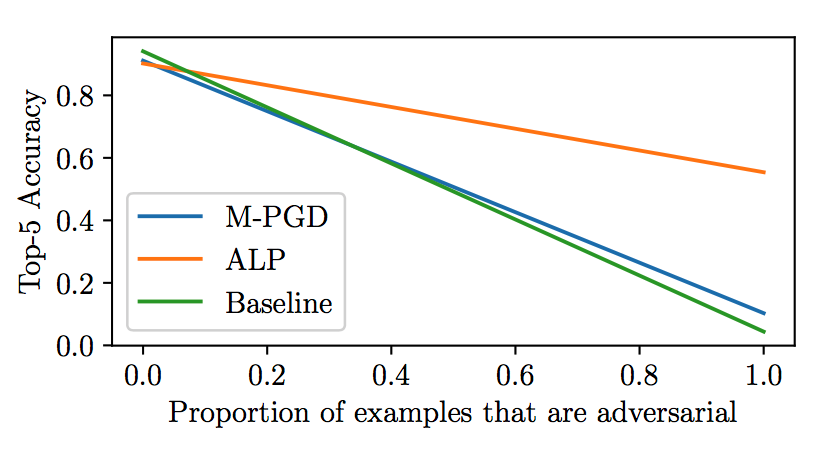
- Prop = 0 is unrealistically optimistic; 1 is pessimistic
- To justify ALP, attackers need to be present > 7.1% of the time
- M-PGD model is never preferred
Moving forward 🔗
- Standard game rules not motivated by concrete security scenarios
- Solutions to \(l_p\) problem e.g. Madry defense: optimize metric directly
- Goodhart’s Law: When a measure becomes a target, it ceases to be a good measure
- Not generalizing to other threat models
Evaluating SOTA defense realistically 🔗
- Madry defense on MNIST unbroken within \(l_\infty\) rules
- Suppose defense is for revenge porn attack (get photos of specific person past ML detector); MNIST as proxy
- “Modify background pixels” attack
- “Lines” attack; required 6 (median) queries to find an error
- Defense only designed against small perturbations in \(l_1\) and not other metrics, let alone content preservation

Don’t forget simpler attacks 🔗
- Explore robustness to whitebox adversary in untargeted content preservation setting
- But also robustness to high-likelihood, simplistic blackbox attacks (e.g. test set attack, simple transformations)
- Content preserving image transformations remains largely unexplored in the literature
- Transformations considered in Engstrom et al. [107] and Verma et al. [122] are a good start
Vikas Verma, Alex Lamb, Christopher Beckham, Aaron Courville, Ioannis Mitliagkis, and Yoshua Bengio. “Manifold Mixup: Encouraging Meaningful On-Manifold Inter- polation as a Regularizer”. In: arXiv preprint arXiv:1806.05236 (2018).
Logan Engstrom, Dimitris Tsipras, Ludwig Schmidt, and Aleksander Madry. “A Rotation and a Translation Su ce: Fooling CNNs with Simple Transformations”. In: arXiv preprint arXiv:1712.02779 (2017).
Security-centric proxy metrics 🔗
- Difficult to formalize “indistinguishable”/“content-preserving”/“non-suspicious”
- \(l_p\) metric as a proxy for “indistinguishability” is not grounded in human perception
- Current best proxies for image content similarity rely on deep neural networks (Zhang et al. [123]) - - Cannot measure itself!
- Short-term approach: hold-out distributions of “content-preserving” transformations
- Generalization out of distribution is more reliable evaluation than performance on restricted worst-case attacks (NP-hard evaluation)
- Content-constrained and non-suspicious: seem very domain-specific
- Best to address specific, concrete threats before trying to generalize
- E.g. Defend “voice assistant” attack with user design: notify user for all commands
Conclusion 🔗
- 1. Broaden definition of adversarial examples
- Take extra care to build on prior work on ML security
- Think like an attacker, realistic game rules
- Consider real systems and attacks that exist in the wild
- Develop new abstractions that capture realistic threat model
- 2. Recenter small perturbation defenses as machine learning contributions instead of security
- Errors are still errors worth removing if possible, regardless of source.
- Better articulate motivations for study
Discussion 🔗
- What are the ML-centric motivations for studying \(l_p\) perturbations shown by Szegedy?
- Works on adversarial examples not motivated by security [81, 93, 106, 109–114]
- “Explaining and Harnessing Adversarial Examples”: Alternate way of evaluating model on some out-of-sample points, with norm ball metric: idea that changes smaller than some specific norm should never change the class [93]
- ‘No free lunch’: adversarial training induces more semantically meaningful gradients and gives adversarial examples with GAN-like trajectories
Discussion 🔗
no free lunch: https://github.com/MadryLab/robust-features-code
- Directions on building robustness to content-preserving transformations?
- “Manifold Mixup: Encouraging Meaningful On-Manifold Interpolation as a Regularizer”
https://github.com/vikasverma1077/manifold%5Fmixup
- “A Rotation and a Translation Suffice: Fooling CNNs with Simple Transformations”