Domain Adaptation Via Teacher Student Learning For Speech Recognition
👩🏫➡👩🎓
Presented by Christabella Irwanto
Need for data-efficiency
- Successful deep learning models are immensely data-hungry and rely on huge amounts of labeled data to achieve their performance.
- In context of speech recognition, success relies on the availability of a large amount of transcribed data li17_large.
- Suffer reduced performance when exposed to test data from a new domain.
- Very time-consuming or expensive to transcribe data for a new domain.
Transfer learning
- Definition of domains and tasks pan2009_survey_transfer_learning.
- A domain \(\mathcal{D}=(\mathcal{X}, P(X))\) is defined in terms of
- The feature space \(\mathcal{X}\)
- The marginal probability distribution \(P(X),\) where \(X\) represents the training data samples \(X=x_{1}, x_{2} \ldots x_{n} \in \mathcal{X} .\)
- A task \(\mathcal{T}=(y, f(\cdot))\) is defined in terms of
- A label space \(y\): a set of all actual labels
- An objective prediction function \(f(\cdot)\): used to predict the label given the data, \(f(\cdot) \approx p(y | x)\).
- A domain \(\mathcal{D}=(\mathcal{X}, P(X))\) is defined in terms of
- Given a source domain \(\mathcal{D}_{S}\), source task \(\mathcal{T}_{S}\), target domain \(\mathcal{D}_{T}\), and target task \(\tau_{T},\), transfer learning is learning the target predictive function \(f_{T}(\cdot)=P\left(Y_{T} | X_{T}\right)\) in the target domain \(\mathcal{D}_{T}\) using the knowledge from the source domain \(\mathcal{D}_{S}\) and the source task \(\mathcal{T}_{S}\), such that \(\mathcal{D}_{S} \neq \mathcal{D}_{T}\) or \(\mathcal{F}_{S} \neq \mathcal{T}_{T}\).
Domain adaptation
- Domain adaptation is a form of transfer learning, in which the task remains the same, but there is a domain shift and/or a distribution change between the source and the target kamath19_deep
- Feature spaces are different, \(\mathcal{X}_S \neq \mathcal{X}_T\), e.g. for cross-lingual adaptation where languages have different features.
- Marginal distribution in data are different \(P(X_S) \neq P(X_T )\), e.g. for a chat text with short forms and an email text with formal language both discussing sentiments.
Speaker adaptation
- Adapting to different speakers with different accents etc. is one of the open research problems in speech recognition.
- A detailed analysis treating this as a domain adaptation problem with different frameworks wang2018empirical
Setting the context
- The latest work by the Microsoft Cortana Voice Assistant team is “Domain adaptation via teacher-student learning for end-to-end speech recognition” meng19_domain , which builds on prior work in teacher-student learning including “Large-scale domain adaptation via teacher-student learning” li17_large and “Conditional teacher-student learning” meng19_condit, all from the same team.
T/S learning
- The source-domain model can be effectively adapted without any transcription by using teacher-student (T/S) learning li17_large in which the posterior probabilities generated by the source-domain model can be used in lieu of labels to train the target-domain model
- Does not require transcriptions but instead uses a corpus of unlabeled parallel data.
- However, T/S learning relies on the availability of parallel unlabeled data which can be usually simulated/collected easily
Parallel data
- Goal: learn a student network to predict the class labels for its input samples \(\mathbf{X}^{S}=\left\{\mathbf{x}_{1}^{S}, \ldots, \mathbf{x}_{N}^{S}\right\}, \mathbf{x}_{i}^{S} \in \mathbb{R}^{D} S\) by using the knowledge transferred from the teacher network.
- The input sample sequences \(\mathbf{X}^{T}\) and \(\mathbf{X}^{S}\) need to be parallel to each other, i.e, each pair of train samples \(\mathbf{x}_{i}^{T}\) and \(\mathbf{x}_{i}^{S}\) share the same ground truth class label \(c_{i} \in\left\{1,2, \ldots, D_{C}\right\}\)
- There are many important scenarios in which collecting parallel data is relatively simple. E.g. to collect noisy or reverberant data, speech can be captured simultaneously using a close-talking microphone and a far-away microphone.
- For most domain adaptation tasks in ASR, parallel data in the target domain can be easily simulated from source domain data.
- Sometimes cannot do it easily. e.g. adult to kids.
| Source domain | Target domain | How to simulate? |
|---|---|---|
| Clean speech | Noisy speech | Add noise |
| Close-talk speech | Far-field speech | Apply RIR, add noise |
| Adults | Children | Voice morphing |
| Original speech | Compressed speech | Apply codec |
| Wideband speech | Narrowband speech | Downsample/filter |
Diagram
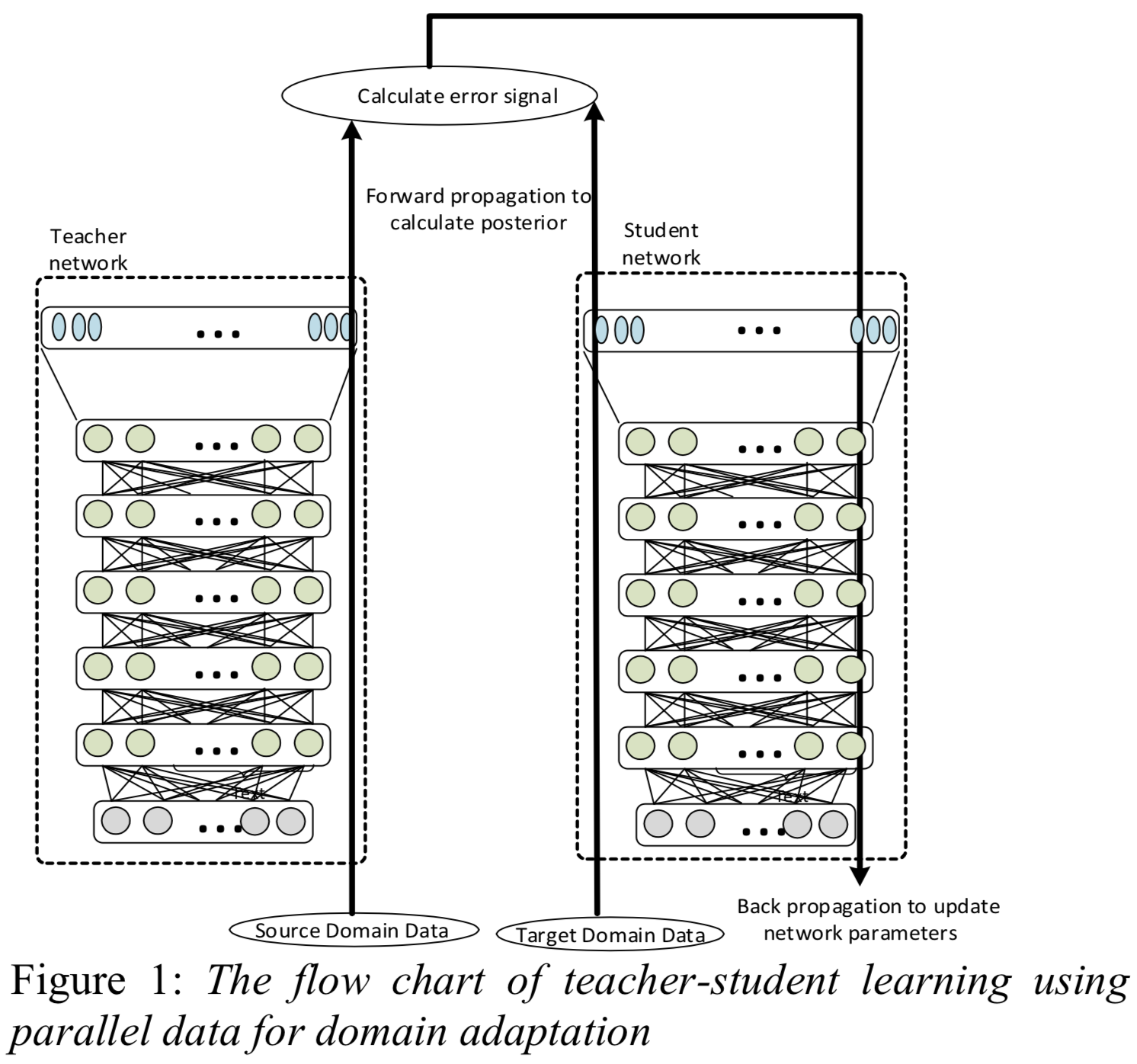
Domain adaptation of a (teacher) acoustic model that is well-trained with source-domain transcribed data to a target domain li17_large
How T/S learning works
- The Kullback-Leibler (KL) divergence between the teacher and student acoustic models’ output senone distributions \(p\left(c | \mathbf{x}_{i}^{T} ; \theta_{T}\right)\) and \(p\left(c | \mathbf{x}_{i}^{S} ; \theta_{S}\right)\), given parallel source and target domain data \(X_T\) and \(X_S\) is minimized by updating only the student model parameters.
- The KL divergence between the teacher and student output is:
- \begin{aligned} \mathcal{K} \mathcal{L}\left[p\left(c | \mathbf{x}_{i}^{T} ; θ_{T}\right) \| p\left(c | \mathbf{x}_{i}^{S} ; θ_{S}\right)\right]=& \\ ∑_{i=1}^{N} ∑_{c=1}^{D_{C}} p\left(c | \mathbf{x}_{i}^{T} ; θ_{T}\right) log \left[\frac{p\left(c | \mathbf{x}_{i}^{T} ; θ_{T}\right)}{p\left(c | \mathbf{x}_{i}^{S} ; θ_{S}\right)}\right] \end{aligned}
- \(i\) is the sample index, \(\theta_{T}\) and \(\theta_{S}\) are the parameters, \(p\left(c | \mathbf{x}_{i}^{T} ; \theta_{T}\right)\) and \(p\left(c | \mathbf{x}_{i}^{S} ; \theta_{S}\right)\) are the posteriors of class \(c\) predicted by the network given the input samples \(\mathbf{x}_{i}^{T}\) and \(\mathbf{x}_{i}^{S}\), respectively.
- Fixing teacher parameters yields the loss function \(\mathcal{L}_{T S}\left(\theta_{S}\right)=-\frac{1}{N} \sum_{i=1}^{N} \sum_{c=1}^{D_{C}} p\left(c | \mathbf{x}_{i}^{T} ; \theta_{T}\right) \log p\left(c | \mathbf{x}_{i}^{S} ; \theta_{S}\right)\)
Successes
- Teacher-student (T/S) learning has been widely applied to deep learning tasks in speech, language and image processing including model compression, domain adaptation, small-footprint natural machine translation (NMT), low-resource NMT, far-field ASR, low- resource language ASR, and neural network pre-training meng19_condit.
- T/S training was shown to outperform the cross entropy training directly using the hard label in the target domain
Advantages
- Compared to one-hot hard labels as the training target, the transfer of soft posteriors well preserves the probabilistic relationships among different classes encoded at the output of the teacher model.
- Soft labels provide more information than hard labels for model training.
- Most importantly, pure soft labels is learning without any hard labels, enabling the use of much larger amount of unlabeled data to improve the student model performance.
Shortfalls of T/S learning
- The teacher model, not always perfect, sporadically makes incorrect predictions that mislead the student model towards suboptimal performance.
- May be beneficial to use hard labels of the training data to alleviate this effect.
- Hinton later proposed an interpolated T/S learning (IT/S) called knowledge distillation, in which a weighted sum of the soft posteriors and the one-hot hard label is used to train the student model.
IT/S, i.e. knowledge distillation
- \[\mathcal{L}_{I T S}\left(\theta_{S}\right)=-\frac{1}{N} \sum_{i=1}^{N} \sum_{c=1}^{D_{C}}\left[(1-\lambda) \mathbb{1}\left[c=c_{i}\right]+\lambda p\left(c | \mathbf{x}_{i}^{T} ; \theta_{T}\right)\right] \log p\left(c | \mathbf{x}_{i}^{S} ; \theta_{S}\right)\] where \(0 \leq \lambda \leq 1\) is the weight for the class posteriors and \(\mathbb{1}[\cdot]\) is the indicator function which equals to 1 if the condition in the squared bracket is satisfied and 0 otherwise.
- IT/S becomes soft T/S when \(\lambda=1.0\) and becomes standard cross-entropy training with hard labels when \(\lambda=0.0\).
- Drawbacks:
- Knowledge distillation requires labeled (transcribed) data.
- Linear combination of soft and hard labels destroys the correct relationships among different classes embedded naturally in the soft class posteriors and deviates the student model parameters from the optimal direction meng19_condit
- Subject to the heuristic tuning of \(\lambda\) between 0 and 1.
Conditional T/S
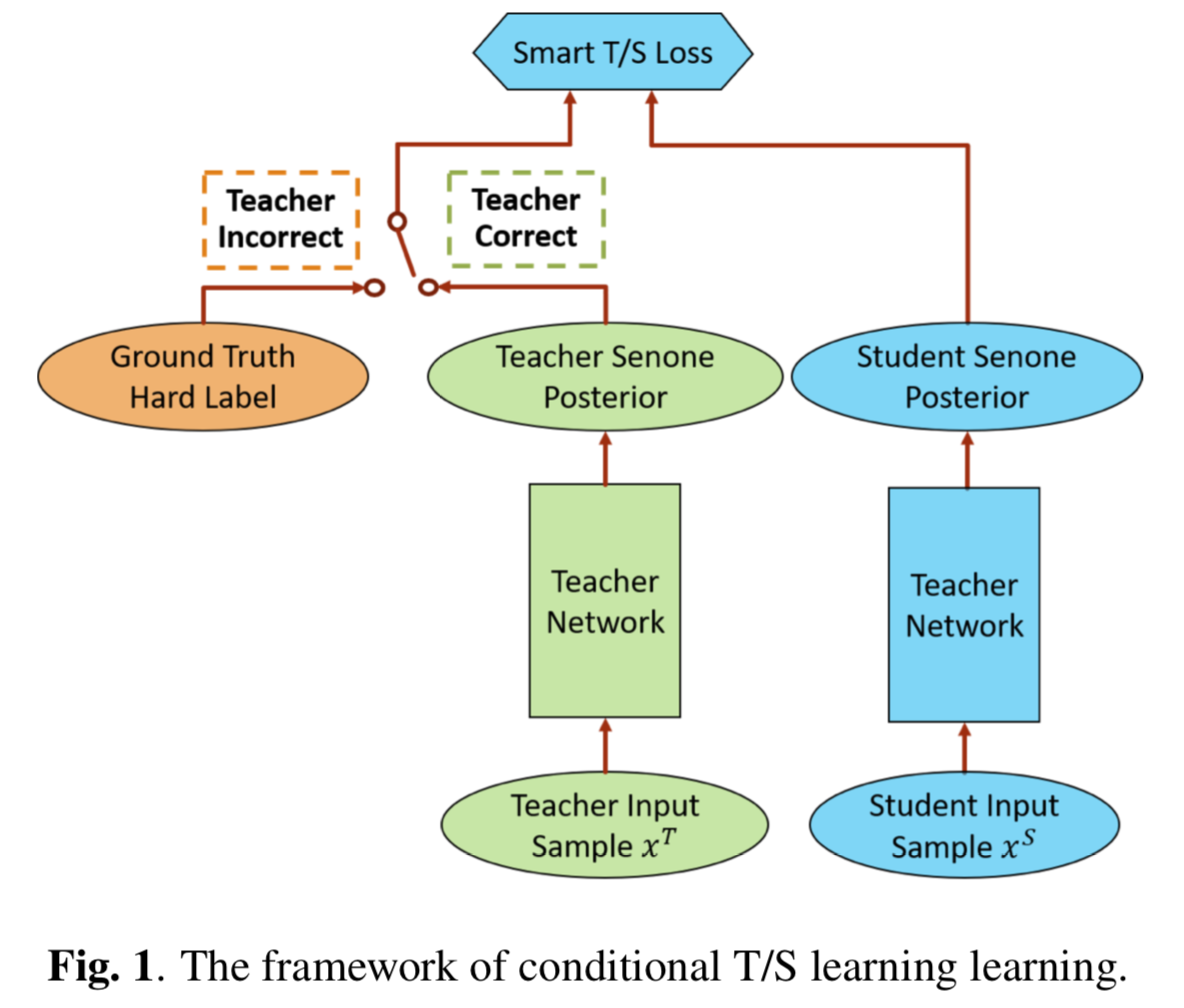
The student network exclusively uses the soft posteriors from the teacher as the training target when the teacher is correct and uses the hard label instead when the teacher is wrong meng19_condit.
Results
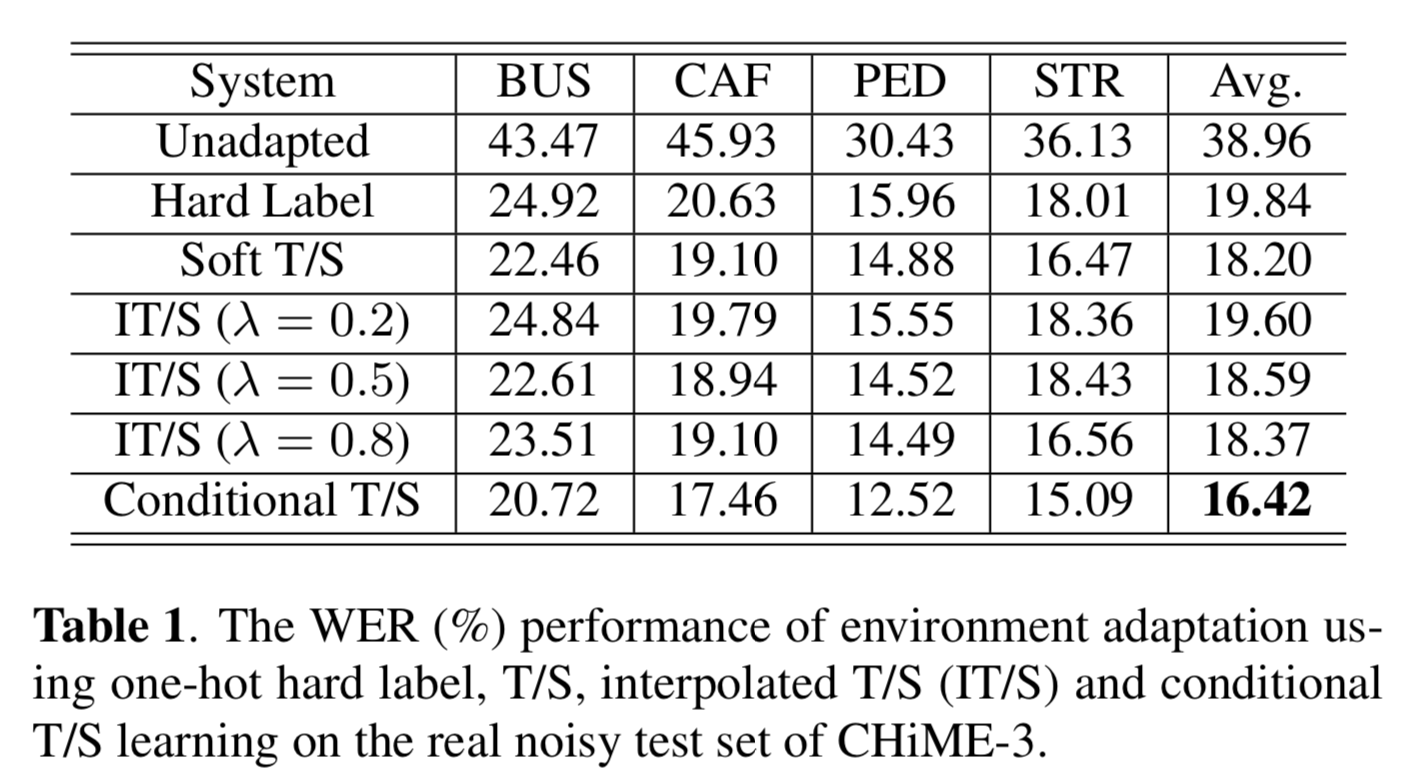
Adaptive T/S
- By taking advantage of both IT/S and CT/S, AT/S adaptively assigns a pair of weights to the teacher’s soft token posteriors and the one-hot ground-truth label at each decoder step, depending on the confidence scores on each of the labels.
T/S learning for AED models
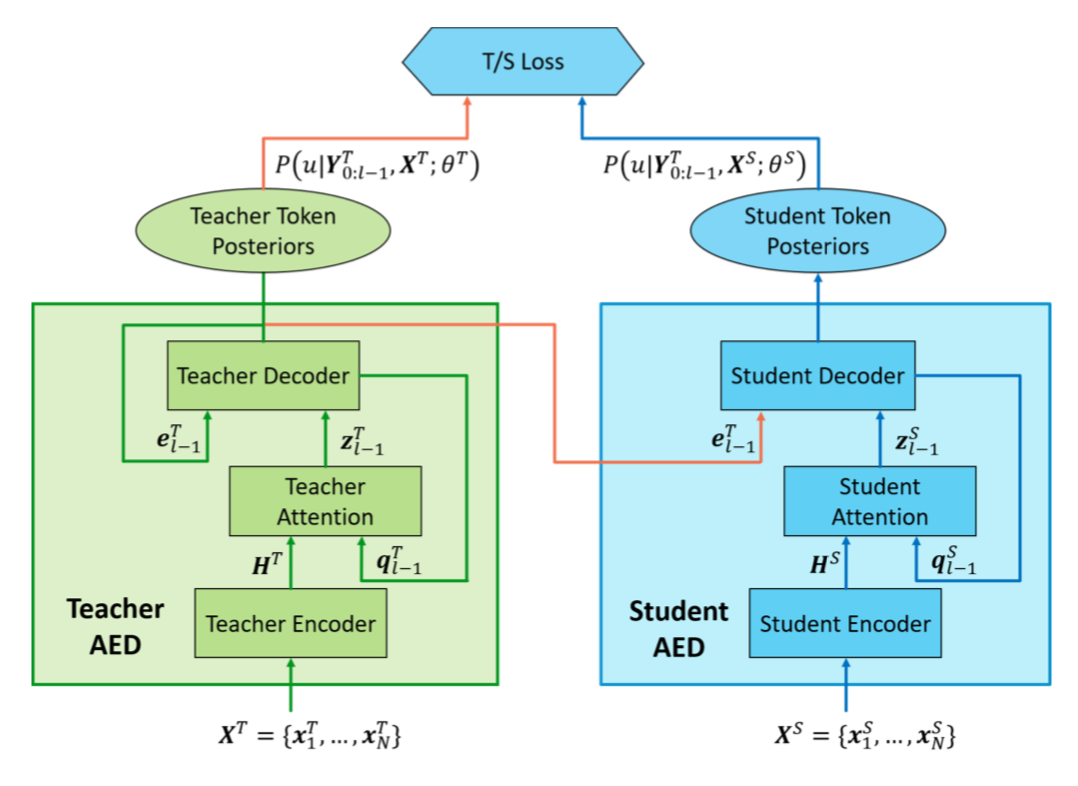
T/S learning for unsupervised domain adaptation of AED model for E2E ASR. The two orange lines signify the two-level knowledge transfer. meng19_domain
AT/S learning for AED models
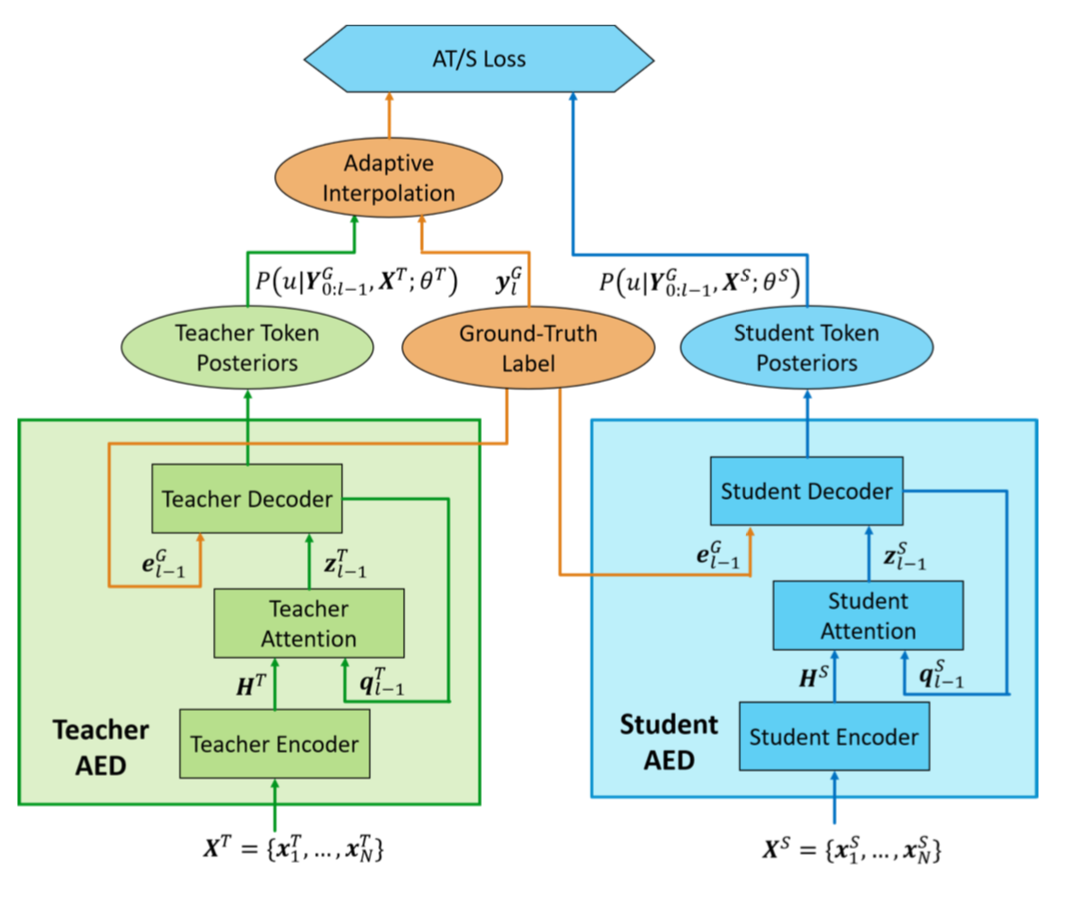
AT/S for supervised domain adaptation of AED model for E2E ASR meng19_domain.
AT/S results

The ASR WER (%) of far-field AEDs trained with CE and AED models adapted by various T/S learning methods to 3400 hours far-field Microsoft Cortana data for E2E ASR on HK speaker test set. meng19_domain
Conclusion
- T/S learning shown to be effective, but requires parallel data which may be difficult to obtain.
- Use domain separation networks (DSN) for domain adaptation on target data with different noise levels meng17_unsupervised. The shared components learn the domain invariance between the source and the target domains. The private components are orthogonal with the shared ones and learn to increase domain invariance. Show significant decrease in the WER over baseline with an unadapted acoustic model with their approach.
- Only one out of many transfer learning techniques outside of speech recognition.
Resources
- Slides and video recording for a talk by Jinyu Li on various deep learning methods for speech recognition, including teacher-student model for domain adaptation, adversarial learning for unsupervised learning without parallel data, and more.
Questions for assignment
- Give some examples of transfer learning and domain adaptation in speech. Explain in terms of domains and tasks, as defined by Pan & Yang.
- What is teacher/student learning useful for?
- What are the drawbacks of teacher/student learning in general (whether soft, interpolated, conditional, adaptive etc.)?
Bibliography
- [li17_large] Li, Seltzer, Wang, Zhao & Gong, Large-scale domain adaptation via teacher-student learning, arXiv preprint arXiv:1708.05466, (2017).
- [pan2009_survey_transfer_learning] Pan & Yang, A survey on transfer learning, IEEE Transactions on knowledge and data engineering, 22(10), 1345-1359 (2009).
- [kamath19_deep] Kamath, Liu & Whitaker, Deep learning for nlp and speech recognition, Springer (2019).
- [wang2018empirical] Wang, Zhang, Wang & Xie, Empirical evaluation of speaker adaptation on DNN based acoustic model, arXiv preprint arXiv:1803.10146, (2018).
- [meng19_domain] Meng, Li, Gaur & Gong, Domain adaptation via teacher-student learning for end-to-end speech recognition, 268-275, in in: 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), edited by (2019)
- [meng19_condit] Meng, Li, Zhao & Gong, Conditional teacher-student learning, 6445-6449, in in: ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), edited by (2019)
- [meng17_unsupervised] Meng, Chen, Mazalov, Li & Gong, Unsupervised adaptation with domain separation networks for robust speech recognition, 214-221, in in: 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), edited by (2017)