Neural Processes for Image Completion 🎨🖌
Presented by Christabella Irwanto
Agenda 🗒
- Motivation
- Related work
- Neural process variants
- Experiments
- Key learnings
- Conclusion
Motivation💡
- Two popular approaches to function approximation in machine learning
- Neural networks (NNs)
- Bayesian inference on stochastic processes, most common being Gaussian processes (GP)
- Combine the best of GP’s and NN’s 🌈
Deep neural networks (NN)
- Training of parametric function via gradient descent
- 👍 Excel at function approximation
- 🙁 Tends to need a lot of training data
- 🙁 (why?) Prior knowledge can only be specified in rather limited ways, e.g. architecture
- 👍 Fast forward-passes at test-time
- 🙁 Inflexible, need to be trained from scratch for new functions
Gaussian processes (GP)
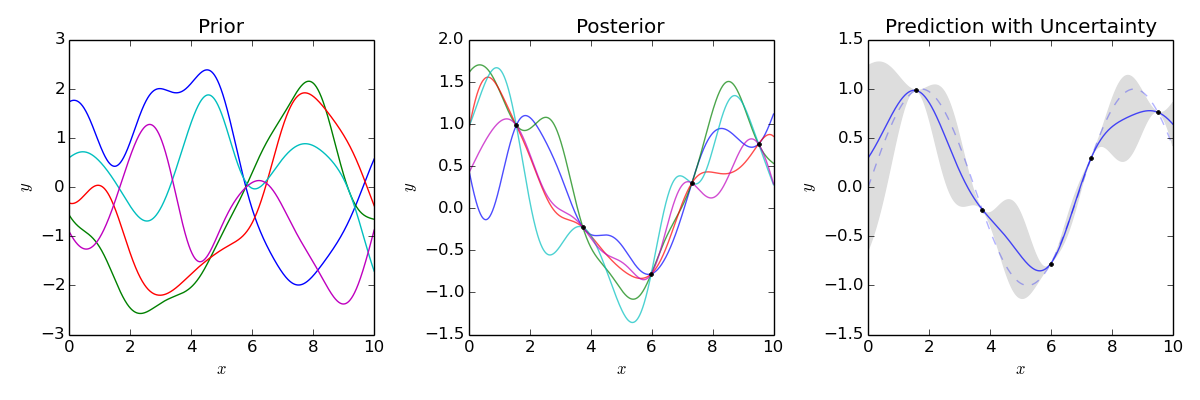
- Compute prior distribution over functions, update belief with data, and sample from distribution for predictions
- Allows reasoning about multiple functions
- Captures covariability in outputs given inputs
- 👍 Encode knowledge in prior stochastic process
- 🙁 Kernels predefined in restricted functional forms
- 🙁 Computationally expensive for large datasets
Best of both worlds 🙌
- Neural processes (NP,CNP) are a class of NN-based models that approximate stochastic processes
- Like GPs, NPs
- model distributions over functions
- provide uncertainty estimates
- are more flexible at test time
- Unlike GPs, NPs
- learn an implicit kernel from the data directly
- computationally efficient at training and prediction (like NNs)
Meta-learning
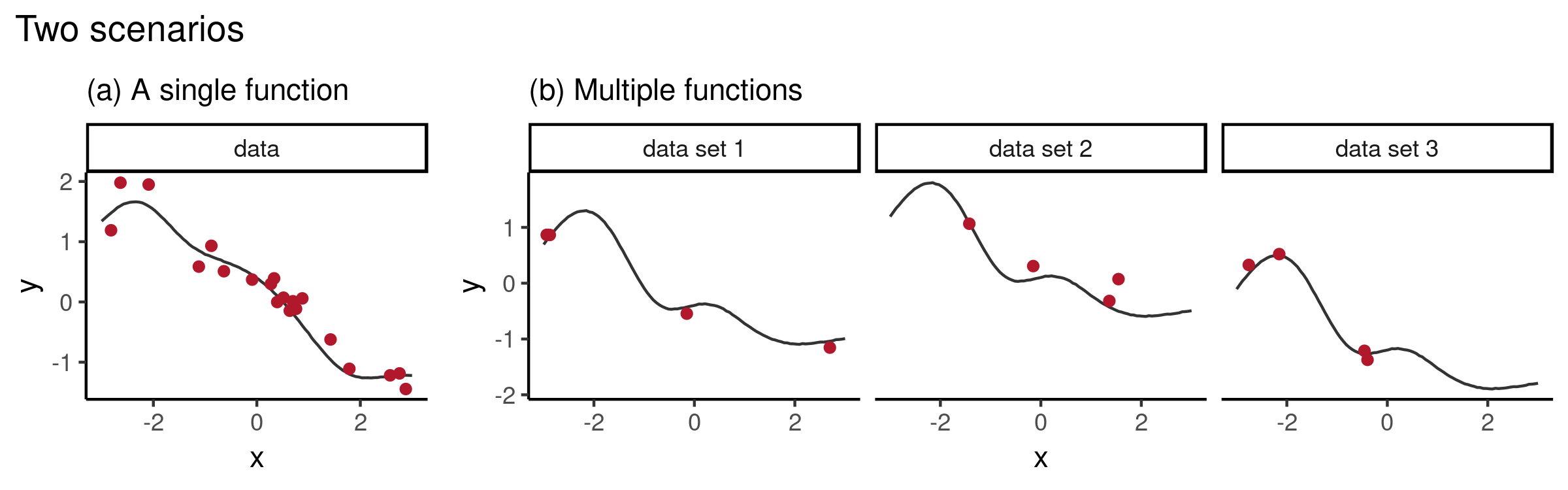
- Deep learning only approximates one function
- Meta-learning algorithms try to approximate distributions over functions
- Often implemented as deep generative models that do few-shot estimations of underlying density of the data, like NPs
- NPs constitute a high-level abstraction; reusable for multiple tasks
Image completion task

- Regression over functions in \(f: [0,1]^2 \rightarrow [0,1]^C\)
- \(f\) accepts pixel coordinate pairs normalized to \([0, 1]\)
- \(f\) outputs channel intensities at input coordinates
- Task is not an end in itself (as a generative model)
- Complex 2-D functions easy to evaluate visually
Neural process variants
- Conditional neural process (CNP)
- Latent variable model of CNP
- Neural process (NP)
- Attentive neural process (ANP)
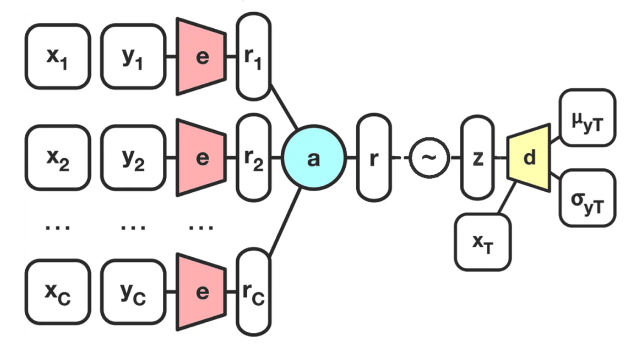
Conditional neural process (CNP)
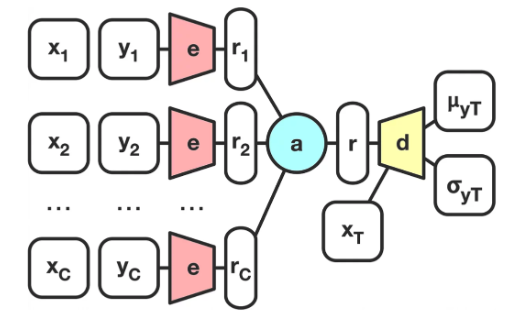
- Accept pairs of context points \((x_i, y_i)\) (coordinates and pixel intensity)
- \((x_i, y_i)\) passed through encoder \(e\) to get individual representations \(r_i\)
- \(r_i\) combined with aggregator \(a\) into global representation \(r\)
- Decoder \(d\) accepts both \(r\) and target location \(x_T\)
Training of CNP
- CNP is approximate conditional stochastic process \(Q_\theta\)
- Minimize negative log-likelihood of the targets' ground truth outputs \(y_i\) under the predicted distribution \(f : X \rightarrow Y = \mathcal{N}(\mu_i, \sigma_i^2)\)
\[ \mathcal { L } ( \theta ) = - \mathbb { E } _ { f \sim P } \left[ \mathbb { E } _ { N } \left[ \log Q _ { \theta } \left( \left\{ y _ { i } \right\} _ { i = 0 } ^ { n - 1 } | O _ { N } , \left\{ x _ { i } \right\} _ { i = 0 } ^ { n - 1 } \right) \right] \right] \]
dist = tf.contrib.distributions.MultivariateNormalDiag(
loc=mu, scale_diag=sigma)
log_p = dist.log_prob(target_y)
loss = -tf.reduce_mean(log_prob)
train_step = optimizer.minimize(loss)
CNP paper results
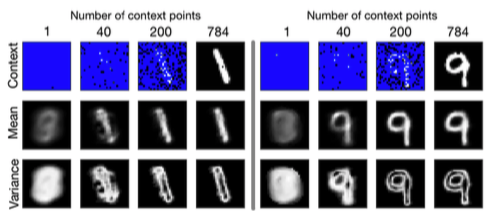
- Outperforms kNN and GP (MSE) when # context points < 50%
- Order of context points is less important (factorized model?)
- \(\therefore\) CNPs learn a good data-specific “prior” (few points needed)
- Uncertainty estimation: variance gets localized to digit’s edges
- But… 🙁 cannot produce coherent samples
- \(\mu_i\) and \(\sigma_i\) will always be same given same \(\left\{ (x_i, y_i) \right\} _ { i = 1 } ^ { C }\)
- Even if observed pixels could conform to 1,4, and 7, CNP can only output incoherent image of mean and variance of all those digits
Latent formulation of CNP
- Let \(r\) parameterize distribution of global latent variable, \(z \sim \mathcal{N}(\mu(r), I \sigma(r))\).
- \(z\) is sampled once and passed into decoder \(d\)
- \(z\) captures the global uncertainty
- allows sampling on global level (one function at a time) rather than locally (one output \(y_i\) for each input \(x_i\) at a time)
Implications for image completion

- Latent CNPs (and NPs) can produce different function samples for the same conditioned observations
- Produce different digits/faces when sampled repeatedly
- Whereas CNPs just output (roughly) the mean of all digits/faces
Training of latent CNP
\[\text {ELBO} = \mathbb{E}_{q(z | C, T)} \left[ \sum_{t=1}^T \log p(y_t^{\ast} | z, x_t^{\ast}) + \log \frac{q(z | C)}{q(z | C, T)} \right]\]
- Like VAE, maximize variational lower bound of log-likelihood
- First term: expected log-likelihood of \(y_t\) under approximate posterior
- Second term: negative KL divergence between prior and posterior
- Instead of a Gaussian prior \(p(z)\), have conditional prior \(p(z|C)\) on context \(C \subset X \times Y\)
- Cannot access \(p(z|C)\) since it depends on encoder \(h\); use approximate \(q(z|C)\)
- Gaussian posterior \(p(z|C, T)\) on both context \(C\) and targets \(T \subset X\)
- Instead of a Gaussian prior \(p(z)\), have conditional prior \(p(z|C)\) on context \(C \subset X \times Y\)
Neural process (NP)
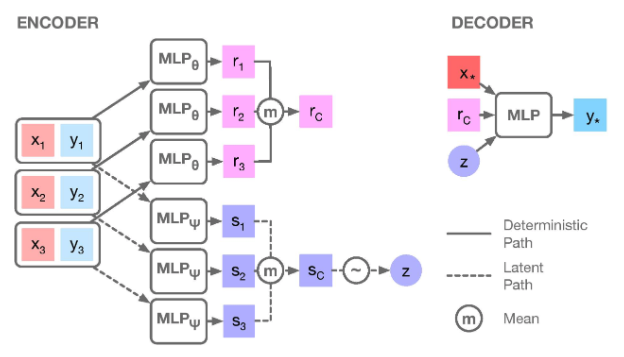
- NPs are a generalization of CNPs, very similar to latent CNP
- But \(e\) is split into two different encoders to produce the global representation \(r_c\) and a separate code \(s_c\) that parameterises \(z\) (instead of directly parameterising \(z\) with \(r\))
- \(d\) also accepts \(r\), not only target location \(x_*\) (i.e. \(x_T\)) and \(z\)
NPs underfit
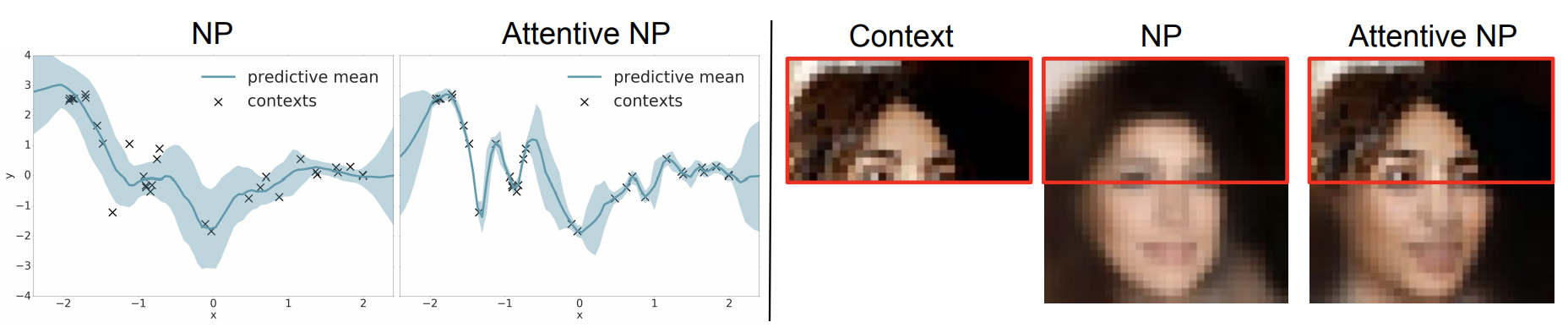
- 🙁 NPs tend to underfit the context set
- Inaccurate predictive means and overestimated variances
- Imperfect reconstruction of top-half
- Mean-aggregation in encoder acts as a bottleneck
- Same weight given to each context point
- Difficult for decoder to learn which context points are relevant for a given target
Attentive neural process (ANP)
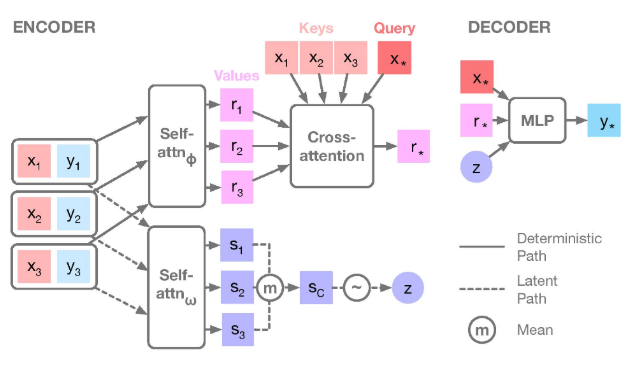
- Aggregator is replaced by cross-attention
- Each query can Rattend more closely to relevant context points
- Equivalent to uniform attention in NP
- Encoder MLP’s replaced with self-attention
- To model interactions between context points
Related work
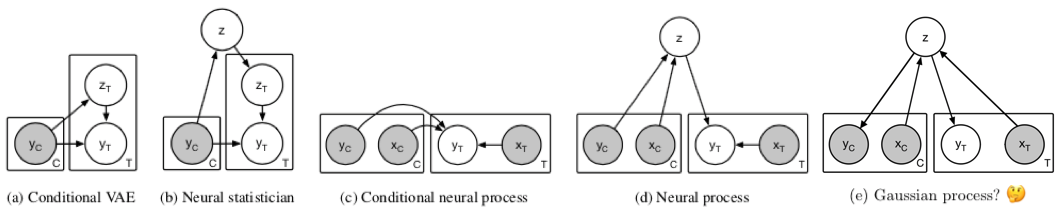
- a) and b) do not allow for targeted sampling at positions \(x_T\)
- Can only generate i.i.d. samples from estimated output density \(y_T\)
- CNP cannot model global uncertainty /distribution over functions; only one \(y_T\) given \(y_C, x_C, x_T\)
- c), d), and e) can sample different functions
- GPs contain kernel predicting the covariance between \(C\) and \(T\), forming a multivariate Gaussian producing samples
Experiments
- CNP latent variable model in PyTorch for \(28 \times 28\) monochrome MNIST images
(e_1): Linear(in_features=3, out_features=400, bias=True)
(e_2): Linear(in_features=400, out_features=400, bias=True)
(e_3): Linear(in_features=400, out_features=128, bias=True)
(r_to_z_mean): Linear(in_features=128, out_features=128, bias=True)
(r_to_z_logvar): Linear(in_features=128, out_features=128, bias=True)
(d_1): Linear(in_features=130, out_features=400, bias=True)
(d_2): Linear(in_features=400, out_features=400, bias=True)
(d_3): Linear(in_features=400, out_features=400, bias=True)
(d_4): Linear(in_features=400, out_features=400, bias=True)
(d_5): Linear(in_features=400, out_features=1, bias=True)
- Architecture modified from unofficial PyTorch implementation github:geniki
Training
400 epochs took 7 hours on NVIDIA Quadro P5000 GPU (Paniikki computer)
Results

- Blue pixels are unobserved; 5 samples per set of context points
10 and 100 context points at epoch 400


- With only 10 context points, generated images are sometimes incoherent
- Increasing to 100 results in more coherent images
300 context points

- Only 38% observed, so still some variation in the different coherent samples drawn
- E.g. in the last column, images of both "3" and "9" are generated that conform to those 100 observed pixels
784 (100%) context points

- When fully observed, uncertainty is reduced and the samples converge to a single estimate
- Even with full observation, pixel-perfect reconstruction is not achieved due to bottleneck at representation level
What about those nice celebrity faces?
- Unable to reproduce results on more complex \(64 \times 64\) RGB CelebA images
- Problems with convergence and lack of implementation details in CNP paper
Key learnings and findings
- Paper omits many implementation details; some details can be filled in with experience and some cannot
- Would have been lost without open-source implementations
- E.g. How does \(r\) parameterize \(z\)? Further MLP layers that map \(r\) to the parameters of Gaussian \(z\)
- Tricks like
sigma = 0.1 + 0.9 * tf.sigmoid(log_sigma)to avoid zero standard deviation…
- Many ways to achieve similar outcomes
- E.g. using or not using VAE reparameterization trick when sampling latent \(z\)
Conclusion ✨
- Incorporates ideas from GP inference into a NN training regime to overcome certain drawbacks of both
- Possible to achieve desirable GP-like behaviour, e.g. predictive uncertainties, encapsulating high-level statistics of a family of functions
- However, challenging to interpret since effects are implicit
- NPs are ultimately still neural network-based approximations and suffer from problems such as the difficulty of hyperparameter tuning/model selection
Lingering doubts 🤔
- Section 3.2 Meta-learning of CNP: "the latent variant of CNP can also be seen as an approximated amortized version of Bayesian DL (Gal & Ghahramani, 2016; Blundell et al., 2015; Louizos et al., 2017; Louizos & Welling, 2017)"
- “CNPs can only model a factored prediction of the mean and the variances, disregarding covariance between target points”
- “Since CNP returns factored outputs, the best prediction it can produce given limited context information is to average over all possible predictions that agree with the context.”
Inference in NP

- How does the approximate posterior look like in terms of the network architecture?
- How does conditional prior \(p(z|C)\) depend on encoder \(h\) (making it intractable)?