I wrote more in this stackoverflow answer.
SVMs and decision trees are discriminative because they learn explicit boundaries between classes. SVM is a maximal margin classifier, meaning that it learns a decision boundary that maximizes the distance between samples of the two classes, given a kernel. The distance between a sample and the learned decision boundary can be used to make the SVM a “soft” classifier. DTs learn the decision boundary by recursively partitioning the space in a manner that maximizes the information gain (or another criterion).
| Generative | Discriminative | |
|---|---|---|
| Supervised | Naive Bayes, Exemplar-CNN | SVM, logistic regression, deep neural networks |
| Unsupervised | LDA, normalizing flows | monocular depth and optical flow models |
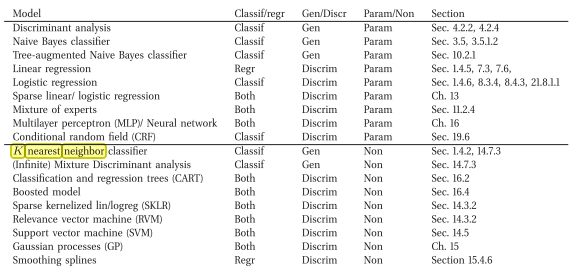
Figure 1: Machine Learning A Probabilistic Perspective by Murphy, Kevin P. (2012)
Resources 🔗
- With respect to comparing canonical examples of discriminative vs generative classifiers (logistic regression and Gaussian naive Bayes respectively), I found this book chapter to be very accessible: cs.cmu.edu/~tom/mlbook/NBayesLogReg.pdf
- To summarize, Logistic Regression directly estimates the parameters of P(Y|X), whereas Naive Bayes directly estimates parameters for P(Y) and P(X|Y). We often call the former a discriminative classifier, and the latter a generative classifier. Ng & Jordan (2002) show, that in several data sets Logistic Regression outperforms GNB when many training examples are available, but GNB outperforms Logistic Regression when training data is scarce.
- Simple definition: https://developers.google.com/machine-learning/gan/generative