A warm-up is a popular strategy, e.g. fast.ai’s 1cycle policy.
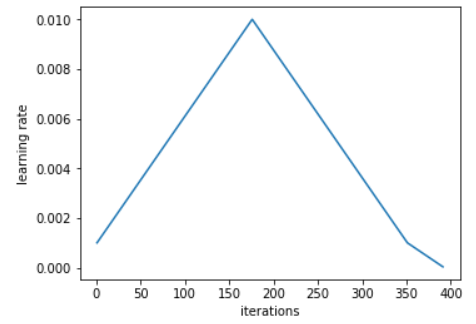
Figure 1: From Another data science student’s blog – The 1cycle policy
According to callbacks.one_cycle | fastai,
Unpublished work has shown even better results by using only two phases: the same phase 1, followed by a second phase where we do a cosine annealing.
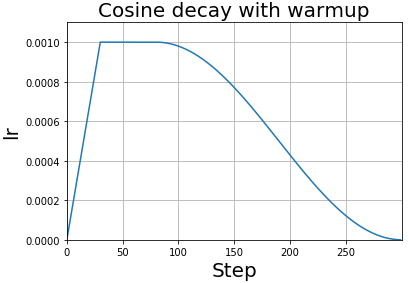
Figure 2: From Bag of Tricks for Image Classification with Convolutional Neural Networks in Keras
Warm-up is a way to reduce the primacy effect of early training examples (prevent overfitting to early examples). Using too large learning rate may also result in numerical instability especially at the very beginning of the training, where parameters are randomly initialized.
For a TensorFlow 2.0 example, refer to TensorFlow learning rate schedule.